|
I finally got around to reading through the 'Curriculum 2019' announcement the Institute made last year. Over the last couple of years, the Institute has carried out a comprehensive review of the qualification process. Based on this they then launched a new curriculum, called Curriculum 2019, which is due to be phased in over the next two years. Some of the changes seem positive, but there's still some fundamental issues that I have with the exams, I thought this would be a good time to write about them. First let's look at the new exams: CS 1 - Actuarial Statistics CS1 looks to be largely just CT3 with a little bit of CT6. The weighting of the subsections for Cs1 will be:
My only comments on this would be that I've seen Regression models used in practice only once while I've been working. It does seem more common to use them in econometric models, and to a lesser extent they do seem to be used in banking/investments environment but on the whole I'm not sure how relevant they are to the work carried out by most actuaries. It could be argued that Regression Models are a useful precursor to the much more powerful and widely used Generalised Linear Model, but I'm not sure it warrants a 30% weighting here. Other than that, this module looks sensible. CS 2 - Actuarial Statistics CS2 is mainly based on the old CT4, and also has some of the CT6 topics which were not included in CS1. The subsections are:
The big point to note here is the inclusion of Machine Learning for the first time in the actuarial exams, I think this is a long overdue and much needed addition. My only criticism would be that it has not been given a greater weighting in the curriculum. I think the advances in Machine Learning, and the fact that most actuaries are not keeping abreast of the subject, is the biggest threat to actuaries remaining relevant within the larger analytics space. The danger is that actuaries will be increasingly sidelined over practitioners with backgrounds in Data Science and Artificial Intelligence. I would have argued for creating an entire module based on the advances in Data Science which I would have made entirely computer based with a focus on the practical application of the models. In order to make room for an increased focus on Data Science, I would have reduced the time spent on Time Series and Survival Models in this module. Time Series, like Regression Models, are not that widely used in practice as far as I'm aware, with their main uses being limited to econometric models, and to a lesser extent in investment models. This part of the curriculum in my opinion could be moved to the Specialist exams section where relevant without much loss. Likewise for survival models, which outside of life and pensions do not have wider application. CM1 - Actuarial Mathematics CM1 looks like it is mainly based on CT1 and CT5. The subsections are:
The invention of Decrement Models and Life Tables in the 17th century marks the beginning of Actuarial Science as a separate field of study. For this historical reason alone, I don't think there's much chance of them being dropped from the curriculum. Personally I've never liked them, finding them messy, and the calculations fiddly and time consuming. Given the fact that they are not used outside of pensions and Life Insurance I would definitely not complain if they were removed from the Core Principles part of the exams and moved into the Specialist Principles section instead. I think I would definitely recommend to new Actuarial Students that they start with the CS exams or the CB exams before tackling the CM exams. The CM exams, while containing some useful topics, seem on the whole less relevant and less interesting than the material covered in the other exams. If a student came from a STEM background I would probably recommend they start with the CS exams, and if they came from a Economics/Management background I think I would recommend that they start with the CB exams. CM2 - Actuarial Mathematics CM2 is largely based on CT8. The subsections and weightings are:
CT8 is a tricky exam to judge, I personally enjoyed studying it, yet I'm once again not sure how useful a lot of the material is. Actuaries have often been accused rightly or wrongly of being out of touch with developments in related branches, and I think this was true of the advances in Financial Mathematics 20 years ago. Historically Financial Mathematics had an independent development to Actuarial Science, and for a long time the advances in Financial Mathematics, such as the Captial Asset Pricing Model (CAPM), or the Black Scholes Option Pricing Model, were largely ignored by the Actuarial Profession. An attempt was made to correct for this, and the CT8 module was invented. The issue now is though, that CT8 still has a relatively high weighting in the exams as a whole. Returning to my point about Machine Learning, the Institute has given Option Pricing (an obscure part of investment theory) twice the weighting of the entire subject of Machine Learning! The second worry I have about the CM2 syllabus is that since the Financial Crisis, Financial Mathematics has advanced considerably, with some topics falling out of favour (one such example being the Black-Scholes Option Pricing Model) and other topics have gained favour, yet the syllabus does not seem to have changed in line with these developments. The other exams in Curriculum 2019 are basically one to one replacements of current exams, so I won't go through them in detail. I will mention a few broader changes that I would make to the Institute's education policy. 3 Recommendations for a new Curriculum When I was thinking about what I would change about the course notes I had quite a few ideas - include a module on coding, specialise earlier so that GI actuaries don't need to learn about with-profit life insurance contracts, Life Actuaries don't need to learn about the CAPM etc., expand the communications section of the exams (this one in particular would not be popular..), but other than the three I've written about below, all my ideas had pros and cons and I think I could be talked out of them. The three I mention below though though I think have really compelling arguments. Recommendation 1 - Rewrite the Course Notes with the aim of making the subject as easy to understand as possible The process for creating the course notes at the moment is quite convoluted: 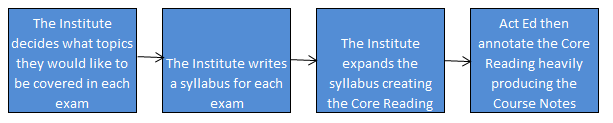 Three main problems stand out for me with this process. Firstly, when Act Ed receive the Core Reading, they are unable to change the ordering of the material. This has the unfortunate effect that often the material is not presented in the order which would make it the easiest to understand.. Material is instead introduced in the the order in which it was included as an item in the syllabus. This quite often necessitates flicking back and forward between pages and not understanding one section until you have read and understood a later section. The second problem with the current process is that by providing an annotated version of the Core Reading, rather than writing the Core Reading in a manner which could be understood without annotation in the first place, we end up with this strange hybrid style which can be a significant barrier to understanding the material. The Core Reading produced by the Institute is often terse, can be inconsistent, and is not always friendly to the reader. The annotations are often well written and help to clarify the unclear sections, but why add the extra cognitive load? Just get someone like Act Ed involved at an earlier stage and write something that is coherent and easy to understand in the first place. The third problem is that there is no single person taking responsibility for the finished product. For an Institution that prides itself on it's approach to accountability I think this is unfortunate. By giving someone with the relevant experience and skills overall creative and technical control over the finished product I believe we would end up with a much more polished and accessible finished product. The syllabus appears to be written by committee, and the Core Reading then expanded out with an awareness that clarifications will be made later. While I think Act Ed do a great job of turning this into something understandable, they are at this point constrained by the presentation of the Core Reading, I think a better product overall could be made by changing this process. Due to the above three issues, when studying for the CT exams I would normally not read the Institute Course Notes at all until just before the exam, instead relying on Course Notes (published online for free!) from uni modules that covered the same material. Due to the exemption system, I found that I could often find modules which covered precisely the same material, but the notes would be written by a university lecturer with a deep understanding of the subject, and also experience of writing notes which are meant to be understood. Whenever I did this, I found the uni notes much easy to work from. Recommendation 2 - Make all the material available online for free. The Course Notes for the actuarial exams are really expensive. This basically restricts the people who are able to study the notes to those who are employed in an actuarial role, and who's employer is willing to fund them in sitting the exams. Given the professions's public charter of "in the public interest, to advance all matters relevant to actuarial science and its application and to regulate and promote the actuarial profession" I think this would be a great idea, as opening up the material to anyone who would be interested in reading them would massively increase the number of people reading the notes. This would particularly lower the barrier for prospective students from poorer backgrounds or countries where the costs would otherwise be prohibitive. To me it's a no-brainer that you should try to reduce the barriers to education as much as possible. Providing free access to allow anyone to study actuarial science is a net public positive with very little downside. There would not be a significant cost in the Institute hosting the e-books on the website for people to download given the web infrastructure is already there. But there would be a significant loss of income. Looking at the Institute's financial accounts for 2016/2017 the total income relating to 'pre qualification and learning development' was around £10 million, the proportion of this which is made up of income related to selling the Course Notes is not specified, but my very rough guess would be that it might be somewhere around a quarter of the total, so £2.5 million. This estimate is just based on the relative cost of the Core Reading (in the range of £50 - 100 for most exams), and the cost of entering the exams (in the range of £220 - £300 for most exams). This would represent around 10% of the Institute's total income, which is significant, but would not be impossible to offset against increases in other areas. Recommendation 3 - move away from written Course Notes to Online Videos Imagine instead of having to read through the Course Notes in order to understand the material, you were instead given one to one private lectures with one of the top educators in the entire country for the six months leading up to the exam. You are allowed to have the lectures at any time of the day, if you prefer mornings you can have them in the morning, if you prefer learning at 2 AM whilst listening to Kerry Perry on full blast then the lectures can be adjusted accordingly. You can repeat any particular lecture as many times as you like, and ask the lecturer to pause half way through a lecture while you think about something. The lecturer is also on top form each lecture, they are giving the best version of that lecture that they have ever given. When you put it like that it sounds pretty good! I think some version of Massive Online Open Courses (MOOCs) or Khan Academy style videos are the future of education. The best metaphor I heard someone use to explain them is if you think back 200 years, if someone had wanted to write the Dark Knight, then Christopher Nolan would have still written the same amazing script, but rather than watching Christian Bale and Heath Ledger (two of the best actors in the world) star in a production which cost 185 million USD to make, you would have had to go to your local theatre and watch the best two actors in your village do their best take on Nolan's script. The budget would have been a fraction of 185 million, and if the actors were having a bad day, or forgot their lines, then they would have had to muddle through. Bale and Ledger had the opportunity of doing take after take until they came up with the perfect version that they were happy with. The video was then post processed and sharpened for months, before being shown to test audience and then further refined based on their feedback. The Institute could be producing 'Hollywood style' videos right now as a compliment to the Course Notes. The Newton - Pepys Problem17/6/2017 I always found it quite interesting that prior to the 19th century, Probability Theory was basically just a footnote to the study of gambling. The first time that Probability Theory was formalised in any systematic way at all was through the correspondence of three 17th century mathematicians, Pierre Fermat (famous for his last theorem), Blaise Pascal (famous for his wager), and Gerolamo Cardano (not actually famous at all) when analysing a problem in gambling called the problem of points. The problem of points is the problem of how to come up with a fair way to divide the winnings when betting on a game of chance which has interrupted before it can be finished. For example, let's say we are playing a game where we take it in turns to roll a dice and we record how many 6s we get, the first person who rolls a total of 10 6s wins. What happens if we are unable to finish the game, but one player has already rolled 8 6s, whereas their opponent has only rolled 2 6s. How should we divide the money in a fair way? Obviously it's unfair to just split the money 50-50 as the player with 8 6s has a much higher chance of winning, but at the same time, there is a chance that the player with only 2 6s might get lucky and still win, so we can't just give all the money to the player who is currently winning. The solution to the problem involves calculating the probability of each player winning given their current state, and then dividing the money proportionally. In order to answer this question in a systematic way, Fermat, Pascal, and Cardano formalised many of the basic principles of Probability Theory which we still use today. Newton - Pepys Problem The Newton - Pepys problem is another famous problem related to gambling and Probability Theory. It is named after a series of correspondence between Isaac Newton and Samuel Pepys, the famous diarist, in 1693. Pepys wrote to Newton asking for his opinion on a wager that he wanted to make. Which of the following three propositions has the greatest chance of success? A. Six fair dice are tossed independently and at least one “6” appears. B. Twelve fair dice are tossed independently and at least two “6”s appear. C. Eighteen fair dice are tossed independently and at least three “6”s appear. Pepys initially believed that Option C had the highest chance of success, followed by Option B, then Option A. Newton correctly answered that it was in fact the opposite order and that Option A was the most likely, Option C was the least likely. Wikipedia has the analytical solution to the problem. Which comes out as: 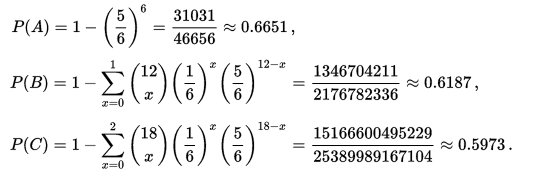 There's a few things I find really interesting about Newton and Pepys's exchange. The first is that it's cool to think of two very different historical figures such as Newton and Pepys being acquainted and corresponding with each other. For me, it makes them much more human and brings them to life the fact that they were both living in London and moving in the same social circles at the same time. Another interesting point is that once again, we see that Probability Theory has been advanced again due to the desire to make money from Gambling. Finally I think it's cool that Pepys was able to ask one of the greatest physicists of all time for a solution to the problem, yet the solution is trivial now. Luckily Newton was able to provide Pepys with an answer, though it might have taken Newton quite a while to calculate, especially for Option C. But you could give the problem to any student now who has access to a computer and they would be able to give you an answer in minutes by just simulating the problem stochastically. Stochastic modelling always seemed like a new form of empiricism to me, whereas calculating the answer with a computer analytically still seems like a-priori reasoning. Newton probably did compute the answer analytically by hand, but he would not have been able to simulate 50,000 simulations of the game by hand. It's fundamentally a different kind of reasoning, and the closest he could have got would have been to play the game 50,000 times and record the average. Stochastic Model To calculate this myself I set up a Monte Carlo model of the game and simulated 50,000 rolls of the dice to calculate the expected probability of each of these three options. 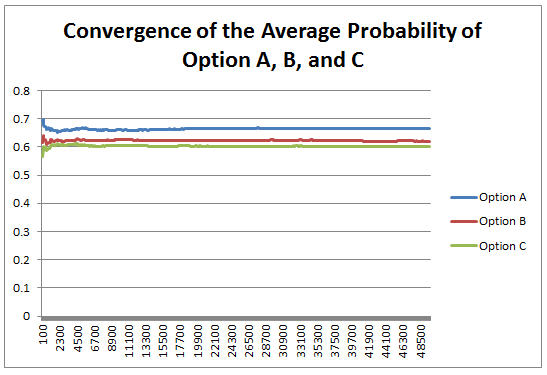 We can clearly see from this graph that Option A is the most likely Option of the three, with Option C being the least likely. We can tell all of this by just setting up a model that takes 5 minutes to build and give an answer in seconds. It makes you wonder what Newton would have been able to manage if he had access to the computing power that we take for granted now. Sources: Wikipedia: en.wikipedia.org/wiki/Newton%E2%80%93Pepys_problem An Article by Stephen Stigler: arxiv.org/pdf/math/0701089.pdf Bitcoin Mining10/6/2017 J.P. Morgan announced recently that they have developed their own Ethereum derivative called Quorum. It is designed to be a platform for smart contracts and a distributed ledger based on Blockchain technology. www.jpmorgan.com/country/US/EN/Quorum HSBC, Bank of America, and Merrill Lynch, have also announced they are setting up a Blockchain ledgers system for clearing inter-bank transactions: www.cityam.com/257426/blockchain-technology-could-revolutionise-global-trade And Microsoft and IBM are setting up Blockchain platforms that they can sell to other business, dubbed Blockchain-as-a-service (Baas) www.coindesk.com/ibm-vs-microsoft-two-tech-giants-two-blockchain-visions/ The info that's been released by these companies about how the technologies will actually work is rather sparse though. There seems to be a lot of buzz, but still no clear consensus on exactly how these technologies will work in practice. In order to try to understand how Blockchains might be important I did some more reading on how they work as part of the Bitcoin protocol, but I actually found myself getting really interested in some of the details of Bitcoin Mining. One of the books I read was the excellent 'Mastering Bitcoins' by Andreas Antonopoulos. It works through all the nitty gritty technical details of the Bitcoins protocol and it really helped crystallise my understanding of some of the technical details. Metaphors about signatures, ledgers, or Alice sending Bob a box with two padlocks on it will only get you so far, at a certain point you need to read through the actual algorithms that are used, and review some source code. So what is Bitcoin Mining and why is it so interesting? What is Bitcoin Mining? Mining is the process by which new transactions are sent over the Bitcoin network and also the process by which new Bitcoins are created. The term Bitcoin Mining is actually a bit of a misnomer, as the creation of the new Bitcoins is not a necessary part of Mining. Even if no new Bitcoins were created, the process of Mining would be the same, and just as important, as it is the mechanism by which transactions are processed within the Bitcoin network. The network is configured so that approximately every ten minutes one of the miners currently attempting to mine the Bitcoin network will find a solution to the hashing problem which will have the following effects:
In essence, assuming the network is not overloaded by transactions (which at the moment it is due to something called the block size limit controversy, which I might blog about another time) every ten minutes all the new transactions which have been created in the last ten minutes will be processed and sent across the Bitcoin network. All these transactions will be included in the latest block which will be added to the end of the Bitcoin Blockchain. The person who mined this latest block will receive a reward of 12.5 new Bitcoins, and all the transaction fees from the last ten minutes. One thing that I didn't understand when first reading about Bitcoins, is that there is only one Blockchain at any one point (barring something going wrong), and that all transactions across the entire Bitcoin network are processed by a single miner in a single Block which is added to the end of the Blockchain. The problem which miners need to solve in order to create a new block in the Blockchain is to find a hash generated by running the the SHA256 algorithm twice on the new block so that the number of leading zeros of the hash is less than the current difficulty specified by the bitcoin network. SHA256 is basically just a complicated algorithm that produces outputs that are effectively random. They are random in the sense that it is impossible to predict what output you will get for a given input, but if you use precisely the same input you will get the sense answer every time. If this sounds a bit complicated, don't worry, it took me ages to get my head around how it all works. Effectively, there is no way to shortcut the above process, SHA256 was designed so that there is no way to predict an input which will generate a given output. If I change the input by a tiny amount, the output will change completely, and there is no pattern to how the output is effected by a chance in the input. The only way to find a valid output is to brute force the problem. So essentially, the only way to mine a new block is to repeatedly attempt to create a new block using all the information about the transactions you would like to include and adding an arbitrary string to the end of the transactions, which you vary every time you calculate the hash of this input, until you find a value that satisfies the conditions set by the Bitcoin network. If someone else finds a solution before you, then everyone starts again with the new set of transactions. Total Hashing Power On average, every ten minutes somewhere in the world a miner will find a valid solution and mine a new block. Whenever the average time to find a solution gets too high or too low, the difficulty of the problem is decreased or increased automatically so as to bring the average time closer to ten minutes. The problem that needs to be solved by the Miners was designed in a clever way so that it could be made arbitrarily hard or easy depending on how many miners are attempting to Mine the network. What is the monetary value of successfully mining a Bitcoin block? We can easily check this by looking at the average transaction fees from the last few blocks that have been mined. For example in the latest block : blockchain.info/block/0000000000000000010465d2dc60e5bf41911b98411ee6b04632a97af41a5df9 The miner received a reward of 12.5 Bitcoins, and also received 1.5 Bitcoins in transaction fees. At today's exchange rate, a Bitcoin is worth around 3,000 USD, which means each block is worth 42,000 USD to the miner at today's exchange rate. Given six blocks are mined per hour, 24 hours per day. The total value of mining the Bitcoin network is approximately 6 million USD per day, or 2 billion USD per year! Given these massive sums up for grabs, there has naturally been a huge arms race in miners attempting to capture this value. Given the design of the SHA256 algorithm and the fact that the only way to mine Bitcoins is to brute force the problem, the only way to increase your share of the 2 billion USD pa is to increase the number of hashes you are checking per second. In fact we can track the total hashing power of the Bitcoin network and see how this has increased over the last 10 years, I took the following graph from Blockchain.info. 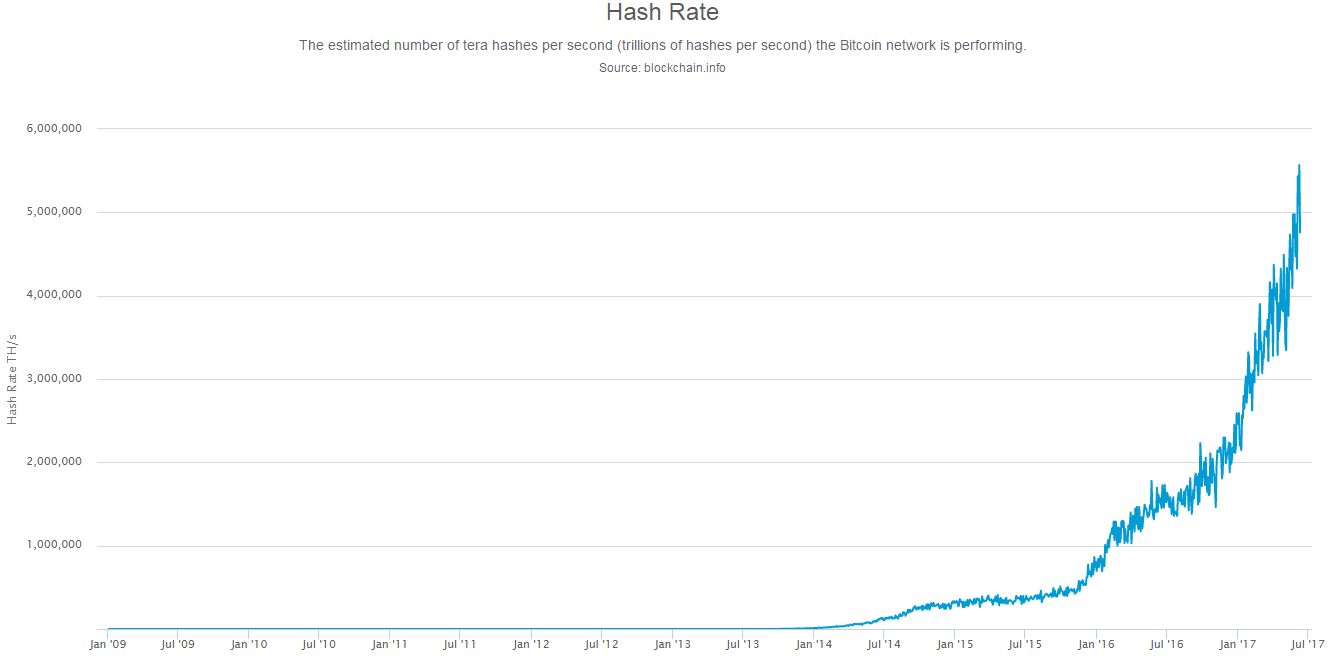 We can see that the total hashing power has been increasing exponentially year on year. The total Bitcoin network is currently estimated as running at around 5,000 PetaHashes per second. Which in long form is 5,000,000,000,000,000 hashes per second. Bitcoin mining was originally carried out by miners using the CPU in a normal desktop computer, but as the number of miners increased, miners started to adapt by using GPU in their computer instead which is much more efficient. Once everyone started to use GPUs though, the next step was for miners to start using something called Field Programmable gate arrays. These are circuits which can be optimised to carry out specific operations very efficiently, so we can set one up that is optimised to carry out the operations that are used in the SHA256 algorithm very efficiently. The latest step in the arms race is the use of circuits called Application Specific Integrated Circuits (ASIC), these are circuits which are designed to do nothing but carry out the specific operations of the SHA256 algorithm extremely efficiently. While the Field Programmable Gate Arrays had been optimised by the people who had bought them to carry out the SHA256 algorithm, the ASICs can do nothing but carry out the algorithm. So due to the fact that the Bitcoin network uses the SHA256 algorithm to validate blocks, we have the weird situation that manufacturers have mass produced ASIC which have the sole function of carrying out the SHA256 algorithm millions of times a second. Who would have guessed that that would have happened ten years ago? The Mining Arms Race The point to remember when thinking about mining is that once the processing power of miners gets above a very small initial threshold, there is no benefit to the network as a whole in increasing the amount of total processing power. The Bitcoin network naturally increases the complexity of the problem that miners need to solve if the total level of hashing increases, so that it always takes approximately ten minutes to mine a block. Bitcoin mining really is an arms race in that if all miners agreed tomorrow to reduce their mining output by 90% there would be no negative effect on the network as a whole, and everyone would still receive the same share of the mining reward. Yet, as soon as one miner starts mining in a much more efficient way, all other miners need to do the same or risk losing out. What does it matter if all this effort is going into mining Bitcoins? The issues is that due to the sums involved, we are now globally spending a huge amount of money and computation power on carrying out what effectively counts as pointless calculations. If aliens visited us tomorrow they'd probably ask why we have a network of computers set up which are carrying out quadrillions of calculations per second of the same fairly uninteresting algorithm. Let's try to put the Bitcoin network into some context. For comparison, the largest Supercomputer in the world is currently the Sunway TaihuLight system at the National Supercomputing centre in Wuxi, China. It has over 10 million cores, and a max speed of 93 PetaFlops per second. Which means it can perform approximately 93,000,000,000,000,000 floating point operations per second. How does this compare to the total bitcoin network? It's impossible to compare the network directly given the fact that so much of the current hashing power is dominated by ASICs which are unable to do anything other than calculate the hash function. We can however attempt to make some comparisons by using other metrics as proxies. When I looked at the most common ASIC used by miners, the Antminer S7 looks to be one of the most widely used circuits by amatuer Miners. It has a hashpower of 4.73 TH/s and comes at a cost of 500 USD. If we divide the total hashing power of the network by the hashpower of the S7, we can derive a (very) rough estimate of the total cost of the hardware currently used in the bitcoin network. This comes out as 500 USD * 5,000 Quadrillion / 4.73 Trillion = 528m USD. We'll use this number later on to estimate the size of the supercomputer we could have brought instead. Since the above estimate is so rough, let's think another way to estimate the total cost of the computing power making up the Bitcoin Network to give ourselves a range of values. If we think instead about the average annualised mining reward from the Bitcoin Network over the last year, and then think about the kind of investment returns Miners would be expecting from the investment in hardware, this will give us another estimate of the total amount spent on Mining equipment across the Bitcoin network. The average Bitcoin price over the last year, according to CoinDesk was 971 USD. I've put an image of the graph of the price over the last year below, but for the calculation I downloaded the Daily mid-price and then averaged accross the year. Assuming 14 Bitcoins received per block mined as per our analysis above, and 6 blocks mined per hour over the year we get a value of around 700 million USD as the average amount that the network as a whole received for mining bitcoins in the last year. 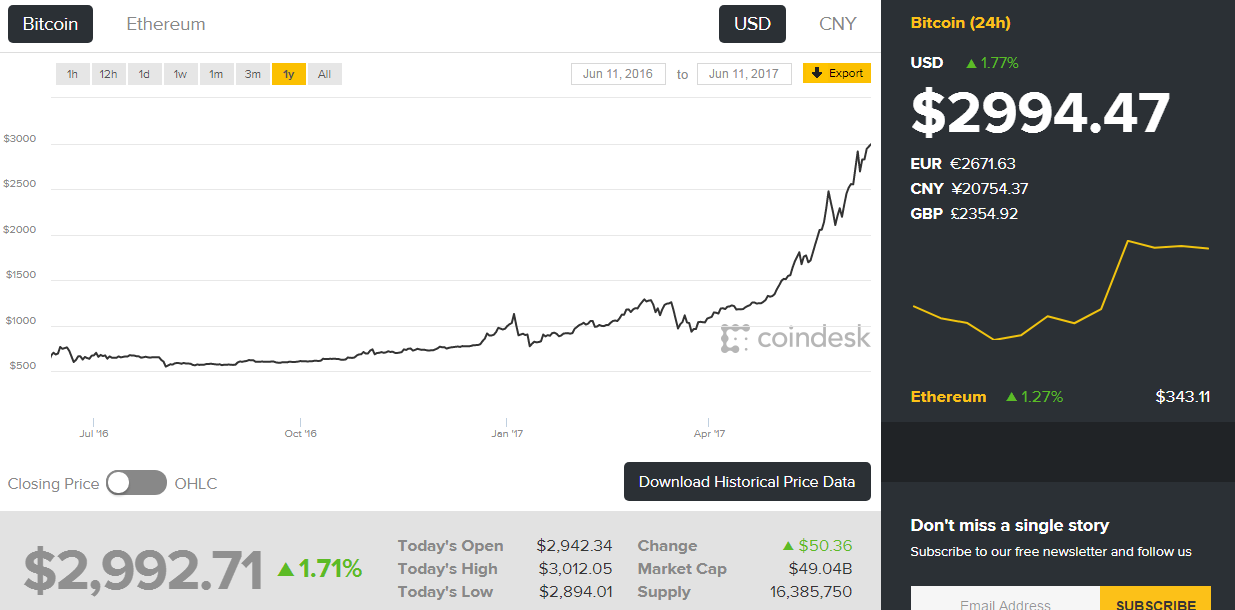 Assuming a rate of return commensurate with the risk (let's say a range of 50% to 100%) and assuming this rate of return includes the cost of electricity. We are looking at a capital value of between 700 million/1 and 700 million/0.5 currently invested in mining the Bitcoin network. This alternative estimate gives us a range between 700 million USD and 1.4 billion USD spent on the hardware currently being used to mine Bitcoins. If we take this dollar value of the computing power being used to mine the Bitcoin network and compare it to the FLOPs per Second per dollar of the largest supercomputers in the world we can estimate the speed of the supercomputer we could have purchased instead. The Sunway TaihuLight system, which is currently the most powerful in the world, is estimated to cost around 273 million USD. So by this metric, the Bitcoin network could be said to be twice as powerful, 3 times as powerful, or even 5 times as powerful as the world's largest supercomputer depending on which estimate of the cost of the Bitcoin hardware currently being used. The frustrating conclusion is that we have collectively gathered a network with a total computing power multiple times that of the largest supercomputer in the word and yet all the computation we are carrying out is effectively useless. The proof-of-work underlying Bitcoin is essentially an arbitrarily hard piece of computing who's only utility is to secure the Bitcoin network. Of course this in itself is a valid purpose, but it definitely does not warrant more computing power than the top 5 super computers in the world combined! Gridcoin I'm not the first person to notice this problem and there have been attempts to develop alt-coins which harness this computing power to attempt to solve useful problems. One such alt-coin is Gridcoin, which randomly assigns a reward to a miner who is mining Gridcoin in proportion to the amount of useful computation they have contributed in the last ten minutes. Users of Gridcoin can select which project they contribute computing power to from a centrally maintained whitelist. The whitelist includes projects such as simulating Protein Folding (used in medical research), searching for Prime Numbers, running climate models, and analysing data from particle physic experiments. The current issue with Gridcoin though is that it relies on a centralised system to allocate the mining rewards. This undermines many of the benefits of the Bitcoin system which was designed to be a decentralised, non-trust based system. What we ultimately need is a system which combines the decentralised Bitcoin protocol, with a system that rewards some sort of useful proof-of-work algorithm. |
AuthorI work as an actuary and underwriter at a global reinsurer in London. Categories
All
Archives
April 2024
|
 RSS Feed
RSS Feed