|
Theresa May announced yesterday that the Government is considering plans to remove the triple lock on the Basic State Pension. The reason being that the triple lock is proving to be too generous to pensioners and that the money could be better spent elsewhere. www.theguardian.com/money/2017/apr/26/theresa-may-considering-scrapping-triple-lock-on-pensions I thought I would do some modelling to demonstrate the effect that the triple lock policy has on the total spending on the state pension. We will see that the triple lock is definitely unsustainable over the long term, but that the effect is relatively slow. Just to be clear, this demonstration is not an argument for or against removing the triple lock in the near future. If we believe that Pensioners are currently being being underpaid overall then we may wish to retain the triple lock for longer. If we think that Pensioners are currently being overpaid overall, then we will probably want to remove the triple lock soon. This is just a demonstration of the effect of the triple lock. What is the triple lock? The triple lock on the basic state pension states that the yearly increase in the state pension shall be the greater of:
So this means that the increase will always be at least 2.5%, but if either inflation or the increase in average earnings is greater than 2.5%, then the increase in the state pension will be more than 2.5%. A Stochastic Model of the UK Economy I set up a very basic stochastic model of the UK economy to examine the expected impact of the triple lock on the amount that the UK spends on the state pension as a proportion of the total UK budget. I first began by collecting data on the annual increases in AWE, CPI, and GDP. With this data, I then fitted correlated normal distributions to the annual increments. Once I had paramterised these variables, I then projected the spending on the state pension and also the overall UK spending by these modelled increments, year by year, over 10,000 simulations.. There are definitely more sophisticated and accurate ways of modelling the economy than this, but I think it should be good enough to give useful results. I had to make an assumption about the increase in the total UK Government spending, I decided to model this in line with GDP growth which I think should be a reasonable approximation. I have also used the fact that the UK Government currently spends 12% of the annual budget on paying the state pension as a starting point. 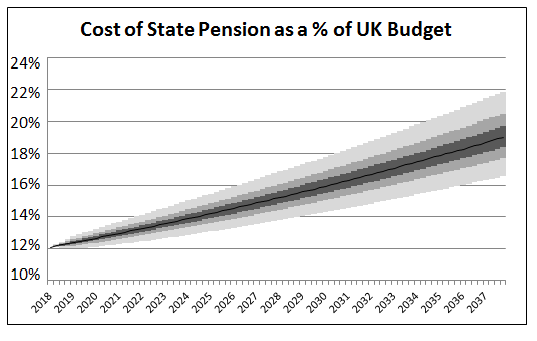 This graph shows the proportion of the UK Budget projected to be spent on the state pension over the next 20 years. I have included a colour gradient on the graph to show the uncertainty in the estimate. The different gradients show the 12.5 percentiles. The black line shows the mid point of the modelled distribution. We see that the average annual amount we expect to be spent on the state pension increases from 12% to over 20% over the course of the next 20 years. Note that this is just based on the increases from the triple lock and does not consider any changes in respect of increasing life expectancy, ageing population, or an increase in the state pension age. Therefore in practice, the effect is likely to be greater than this. An increase to 20% would be equivalent to an additional £62 billion per year in today's money on the state pension. An Alternative View From a more mathematical view, the fundamental reason the triple lock works like this can be seen from the following equation: $$\sum_{i = 2018}^{2037} {max ( a_i , b_i ) } >= max ( \sum_{i = 2018}^{2037} a_i , \sum_{i = 2018}^{2037} b_i )$$ Since we expect average annual earnings to increase in line with GDP in the long term, and we also expect the total UK budget to increase in line with GDP, we will eventually expect any series which is based on a maximum of increases to average earnings, and a fixed floor of 2.5% to reach 100% of GDP, and therefore 100% of the total UK budget. Data Sources GDP data source: data.worldbank.org/indicator/NY.GDP.MKTP.KD.ZG Average Earnings source: www.ons.gov.uk/employmentandlabourmarket/peopleinwork/earningsandworkinghours/datasets/averageweeklyearnings CPI data source: www.ons.gov.uk/economy/inflationandpriceindices/timeseries/d7g7/mm23 Driverless, Autonomous, Self-driving, robotic, drone cars, whatever you want to call them, I think self-driving cars are going to be awesome.. The potential benefits include:
But how far away are we from this being a reality? It seems like we are constantly being told that self-driving cars are just on the horizon, and that wide spread use of self-driving cars will arrive sooner than we think. It got me thinking though, surely even when manufacturers start churning out driverless cars, isn't it still going to take a considerable amount of time before they begin to replace all the cars currently being driven? Most people will not suddenly go out and replace their current car the moment self-driving cars are available on the market.  Replacing all the old cars Almost all cars that are currently being driven today will never be self-driving, it will only be new cars, after a certain point, that will start to be self-driving. So even if all new cars from now on were to be self driving, there would still be a delay as old driven cars were slowly replaced by self driving cars. I thought I'd try to do some modelling to see how quickly would this process might take place. As a starting point, let's assume that we will start to see self-driving cars being produced by 2019. I found the following report from the Department of Transport which details the number of cars on the road today, and the number of new cars registered every year. www.gov.uk/government/uploads/system/uploads/attachment_data/file/608374/vehicle-licensing-statistics-2016.pdf The important statistics are: There are currently $37.3$m cars on the road Each year the number of registered cars increases by approximately $600,000$ Around $3.3$m new cars are registered every year. I then extrapolated these statistics based on three different scenarios: Scenario 1 - All new cars from 2019 onward are driverless 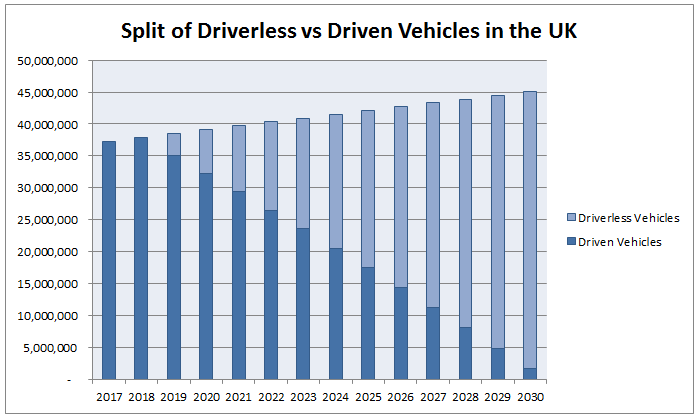 We can see that even under this very optimistic scenario, it's not until 2025 that we will see a majority of cars on the road being driverless. It's probably not reasonable though to assume that all new cars produced after 2019 will be driverless, so let's look at the effect of slowing increasing the proportion of new cars that are driverless. Scenario 2 - Assuming linear increase in % of new cars produced which are Driverless between 2019 and 2030 In this scenario we assume that in 2018 all new cars are driven, and that by 2030 all new cars are driverless, and we assume a linear increase in the % of new cars which are driverless between these two years. 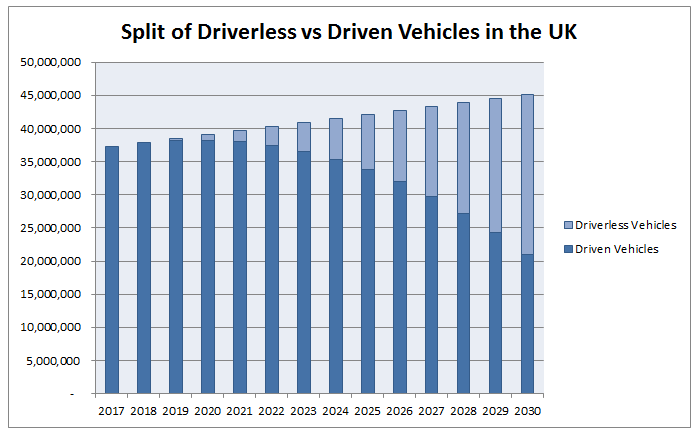 We see that under this scenario, it's not until 2030 that we start to see a majority of driverless cars on the road. To get an alternative view, let's look at a quicker rate of adoption, let's suppose instead that by 2025, all new cars will be driverless. 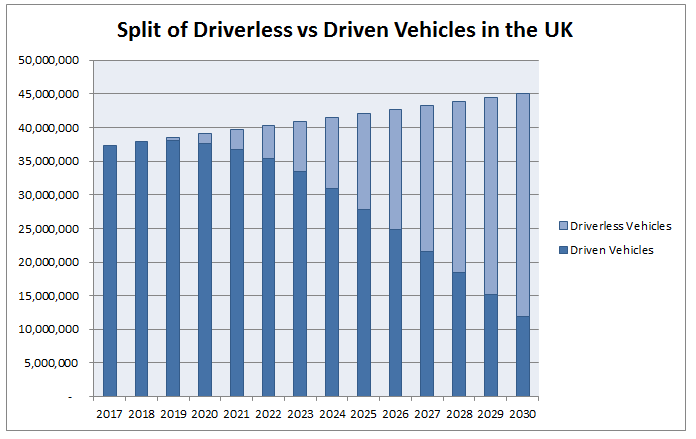 Now we see that a majority of cars are driverless by around 2027, with a strong majority emerging by 2030.  Conclusion Even when we assume that driverless cars will start to be produced by 2019, based on current trends of car replacement, and depending on the speed at which self driving cars are produced, we shouldn't expect a majority of cars on the road to be driverless until at least the late 20s or maybe even early 30s. So when analysts say that driverless cars will be common much sooner than people expect, they need to be careful about how they define common. Bitcoin - Who is Satoshi Nakamoto21/4/2017 Who is the mysterious Satoshi Nakamoto? Let me pitch you an idea for a movie - following the 2007 financial crisis, fed up with the corruption of the modern financial system, a lone genius creates a new virtual currency with which he aims to completely undermine the modern baking system. This new currency allows instantaneous online payments to be made with minimal transaction fees and with almost complete anonymity. Better yet, this system is completely decentralised, requiring no central bank or governing body. To further add to the mystique, our hero decides to eschew fame, remaining completely anonymous while netting himself a cool USD 1 billion in bitcoins. But our hero decides to walk away and leave the USD 1 billion in bitcoins untouched on a public ledger on the internet, proving to the world that he was never in it for the money. All that he leaves behind is a name - ***Cue dramatic music*** - Satoshi Nakamoto, Chuck in some bad guys and a love interest and we've got the making of a Hollywood blockbuster! This is of course the true story of the origins of bitcoin. Unsurprisingly, there have been many attempts to find the true identity of Satoshi Nakamoto, every six months or so a new candidate is found and the media jumps on the bandwagon, but none of the candidates so far have been really convincing. I thought I'd do a bit of digging myself and see what we have to work with, and what we can know for certain., and what we can speculate about.  So what info do we have work with? Satoshi left behind the following:
The Forum Posts Almost all the forum posts are highly technical, and there is very little to be gleaned about Satoshi's identity from the content of the posts. I did look through most of them just in case. But based on an idea in Satoshi's Wikipedia article, I have graphed the timestamps from the forum posts. All the forum posts can be found on the following website, which I scraped using web scraper and then chucked into excel to extract the timestamps: satoshi.nakamotoinstitute.org/ 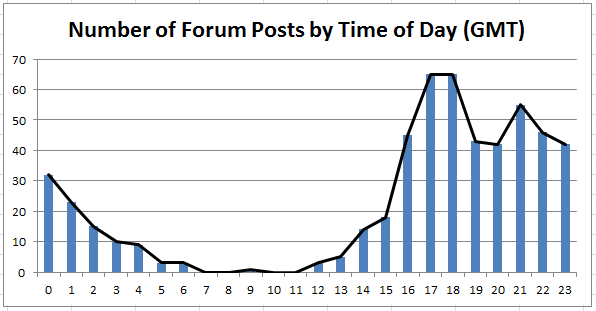 We can see that there is a clear trend for most posts to be made between 4pm and 11pm, with almost none being made between 5 am - 1 pm, suggesting that this is when Satoshi is asleep. Based on most people I know who don't have a 9-5 job, but are still involved in IT, this is a pretty reasonable sleeping pattern for someone living in a GMT time zone. If we assume that Satoshi has a conventional sleeping pattern though, then we would expect him to be living somewhere on the US East Coast. Both of these seem plausible to me, it does gets less plausible though to consider someone living much further east than Europe. I then graphed the weekday of each forum post. Which shows a fairly stable pattern of posts through out the week. Nothing too surprising here.  It has also been noted that the blog posts from Satoshi use British spellings rather than US spelling. Let's also test that. I collected a list of words that are spelt differently in UK and US English, and cross referenced it against the blog posts we scraped earlier. The following words were all used by Satoshi but with the UK spelling. amortised colour decentralised favour fulfil gauge grey greyed labelled labelling liberalising modernised optimised prioritising reorganised This strongly suggests that the author is most familiar with British English over American English. It's also been noted (and I concur) that Satoshi's posts are written like a native English speaker. He uses common idioms well and his grammer and structuring all give compelling reasons to think that he is a native English Speaker .This has been put forward by some as definitive proof that he is British. I'm not so sure though, having met Europeans who through having a lot of exposure to English speakers growing up, now sound like native English speakers when writing or texting. Leaving the blog posts for the time being, let's look at the emails in the mailing list. Mailing List Emails The mailing list was a Cryptography focused mailing list, established in 2000, and can be found through the following link: www.metzdowd.com/mailman/listinfo/cryptography The website gives the following introduction to the mailing list. "Cryptography" is a low-noise moderated mailing list devoted to cryptographic technology and its political impact. Occasionally, the moderator allows the topic to veer more generally into security and privacy technology and its impact, but this is rare. WHAT TOPICS ARE APPROPRIATE: "On topic" discussion includes technical aspects of cryptosystems, social repercussions of cryptosystems, and the politics of cryptography such as export controls or laws restricting cryptography. Satoshi began posting to the mailing list in November 2011, and his first post was an introduction to his new bitcoin system, it gave a brief overview and then linked to the paper he had written which contained the technical details. It therefore seems that the mailing list was a method of generating interest for his already fleshed out system rather than something he contributed to already. I was initially slightly suspicious of how well written the emails are compared to the forum posts. It's been suggested by a few people that Satoshi might actually be the name chosen by a group of collaborators rather than one single person. On consideration though, the mailing list is said to be 'highly moderated' and therefore it should perhaps not be surprisingly that Satoshi has polished his grammar and writing when sending emails to the mailing list. Plus you'd expect quite a bit more care when replying to an email rather than making a forum post. To be honest I struggled to gleam much more from the emails other than a couple of interesting quotes which I've included at the end of this post. The Genesis Block Satoshi created the first block of the first blockchain. Since there were no preceding transactions, Satoshi was able to insert a message into the block. The message he selected was: "The Times 03/Jan/2009 Chancellor on brink of second bailout for banks" This tells us a few things. Firstly, it's evidence that no Bitcoins were mined prior to this date. Secondly, it could be seen as a comment on the financial bailout that was ongoing at the time and which may have cause Satoshi to develop Bitcoin in the first place. And finally, it's another link to the UK, given Satoshi has selected a British newspaper to timestamp his first block. Other Random Thoughts:
Here are some additional thoughts on the Satoshi question which I have included in the hopes that someone else might find them useful. Since Satoshi stopped working on Bitcoin in 2011, perhaps we should be looking for someone who has made interesting contributions to a different project since then? Would a better programmer than me be able to spot idiosyncrasies in Satoshi's coding style which could be traced in other places? What if someone trawled Github and looked for these quirks? Some people have attempted a Stylometric Analysis. I haven't looked into this at all, but it's something I might look into at another point. Satoshi is the Japanese name of the main character (Ash Ketchum) in Pokemon and also the name of the creator of Pokemon, Satoshi Tajiri. Are there any other famous Satoshis? Or Famous Nakamotos? I did a quick google, but I couldn't find anyone who stood out to me. Satoshi was familiar with Mises' regression theorem, which is a pretty niche economic concept from Ludwig von Mises, an economist from the Austrian School. The Austrian School are famously associated with libertarian or right wing anarchist views. Satochi seems pretty au fait with libertarian concepts generally Prior to Bitcoin's rise, crytocurrencies were a very niche interest, perhaps it would be worthwhile to look at who was going to conferences, writing papers, working in the industry, etc. prior to 2007. It should be a relatively small group of people, and you would imagine that Satoshi would have a footprint in there somewhere. Some interesting quotes from Satoshi: Yes, but we can win a major battle in the arms race and gain a new territory of freedom for several years. Governments are good at cutting off the heads of a centrally controlled networks like Napster, but pure P2P networks like Gnutella and Tor seem to be holding their own. ... I appreciate your questions. I actually did this kind of backwards. I had to write all the code before I could convince myself that I could solve every problem, then I wrote the paper. I think I will be able to release the code sooner than I could write a detailed spec. You're already right about most of your assumptions where you filled in the blanks. ... It's very attractive to the libertarian viewpoint if we can explain it properly. I'm better with code than with words though. ... I believe I've worked through all those little details over the last year and a half while coding it, and there were a lot of them. The functional details are not covered in the paper, but the sourcecode is coming soon. I sent you the main files. ... Banks must be trusted to hold our money and transfer it electronically, but they lend it out in waves of credit bubbles with barely a fraction in reserve. Conclusions? To draw a few tentative conclusions, we seem to be looking at: A native English speaker. Who picked a Japanese pseudonym. Who favours British English over US English. Who selected a British newspaper to timestamp his genesis block. Who's background is primarily coding based. Who seems to hold libertarian views and be motivated by libertarian beliefs Who has an interest in Crytography and Crytocurrencies which stretches back to at least 2007. And who appears to be operating either on the East Coast or on a Western European time zone. Surely there can't be many people out there who meet all these criteria? Fact 1 - If Airline Companies were ran like Rocket Companies, a trip from London to New York would cost about $300,000. Prior to SpaceX, launching a a Satellite into orbit was expensive. Really, really expensive. The most commonly used launch vehicle was the Ariane 5, manufactured by the French Company Arianespace, and costing somewhere in the region of USD75 million per launch. SpaceX have stated that their eventual hope is target a cost of USD6 million per launch. How do they hope to achieve a more than 10 times cost reduction? Better Economies of Scale? Improved Manufacturing Processes? Cheap Labour? 3d Printing? Actually none of the above. The answer is actually kind of obvious once you hear it though. They want to make rockets that can be used more than once! As a though experiment, let's apply the concept of reusability to a familiar mode of transport. If we take the most common airliner in the world - the Boeing 737 - then we can compare the cost of a flight with full reusability against the cost of the flight without reusability. A new Boeing 737 costs in the region of USD75 million (depending on the exact model) whereas a return ticket to New York on a Boeing 737 only costs about USD600 per seat. Multiplying the number of seats (~250) by the cost of a one way ticket (~USD300) we see that the total cost of the flight is somewhere around the USD75,000. So each flight costs about 0.1% of the total cost of the airliner. Suppose though, that like a rocket, a 737 could only be flown once. Then all of a sudden, instead of costing less than USD75,000 per flight, the flight would include the full cost of the 737, meaning each ticket would cost around USD300,000! By creating rockets that are reusable, SpaceX hopes to get similar cost savings in the arena of launch vehicles. SpaceX is actually quite close to achieving full reusability, here is a cool video of a Falcon 9 rocket making a vertical landing on a drone ship in April 2016. Fact 2 - It is easier to land the rocket on a Drone Ships than the original launch site In the video above, the Falcon 9 lands on a floating platform in the ocean. Given landing on a ship in the ocean seems to add another layer of complexity to an already difficult task why did SpaceX decide to do this? A few ideas spring to mind, you might think that this is because the rocket is not sufficiently accurate and the drone ship has to be able to move around to get into the right place, or possibly that the ocean is a safer environment to land on given the lack of nearby people or property to damage. Or perhaps SpaceX are doing this as a form of marketing given the fact that it looks pretty cool. However, the actual reason is surprisingly prosaic, and also, once you think about it, kind of obvious again. It'all has to do with how you get a satellite into orbit in the first place. When a rocket attempts to get a satellite into orbit it does not just go vertically up in the air, in order for a satellite to be in a stable orbit, it actually needs to be moving perpendicular to the earth's surface at a very high speed (which can be calculated based on the height of the orbit) in order to not fall back to earth. I wrote a model in Python of a two stage rocket launching a satellite into orbit around earth. I then ran the model multiple times keeping the overall thrust of the rocket exactly the same every time, but varying the initial direction of acceleration. Using this model we can see the large effect that varying the path the rocket takes has on the ease in which a satellite can be put into orbit. In the first video, the launch rocket is sent almost vertically up in the air, and the satellite (the blue part) makes very little progress before it crashes back down to earth. In the second attempt, we angle the rocket towards the horizon more, in this case, by 55 degrees. And we can see that whilst the satellite does not make it into orbit, it does come closer than the first attempt. In the final attempt, we angle the rocket at a 45 degree angle to the horizon. Now we see that the satellite does in fact make it into orbit. Note that the only thing we have changed in all these attempts is the angle of launch, the acceleration of the rocket has not been changed at all. The point to note from all this is that in order to get a satellite into orbit, the rocket that was used to put it into orbit also needs to have a lot of horizontal velocity. There are quite a few simplifications in our model. For example, we have not included air resistance which will have an impact as in practice there will be a benefit in gaining as much vertical height as possible initially so as to reduce air resistance. The model also does not take account of the fact that the mass of the rocket will reduce as it gets higher due to the fuel expended. However neither of these simplifications effects the the general principle of needing horizontal acceleration. To tie it back to our original point, from watching the videos you might be able to tell the problem that SpaceX found themselves dealing with when using this approach. The first stage of the rocket ends up miles away from the launch site! It turns out that for SpaceX, given the location of their launch site, the landing site for these rockets tends to be in the ocean, and this is why that they land the rockets on barges in the ocean.
Fact 3 - The floating ships are named after ships in Iain M. Banks novels
SpaceX have two landing barges (also known as Autonomous Spaceport Drone Ships) that they use to land the rockets on. The barges are called 'Just Read The Instructions' and 'Of Course I Still Love You'. These may seem like very unusual names for SpaceX to pick, unless you spot that they are in fact names of spaceships in Iain M. Banks' Culture series, a series of sci-fi books set in a Utopian future with an interstellar human race. Python Code In case anyone is interested, I have pasted the Python code for the two stage rocket model below. My code was partially based on the following model, which simulates the n-body problem in Python. fiftyexamples.readthedocs.io/en/latest/gravity.html
import turtle
import math
turtle.color("White")
turtle.sety(100)
turtle.color("Black")
turtle.circle(-100)
turtle.seth(90)
turtle.color("Red")
Vx = 0.3
Vy = 0.3
SecondStage = False
for sec in range(3500):
CurrentX = turtle.xcor()
CurrentY = turtle.ycor()
d = math.sqrt(CurrentX ** 2 + CurrentY ** 2)
f = 17 / (d ** 2)
theta = math.atan2(CurrentY, CurrentX)
fx = math.cos(theta) * f
fy = math.sin(theta) * f
Vx += -fx
Vy += -fy
if turtle.pencolor() == "Red":
turtle.goto(turtle.xcor() + Vx, turtle.ycor() + Vy)
if d < 100:
turtle.color("white")
if sec == 250:
SecondStage = True
New = turtle.Turtle()
New.color("white")
NewCurrentX = CurrentX
NewCurrentY = CurrentY
New.goto(NewCurrentX,NewCurrentY)
New.color("blue")
VNx = Vx + 0.05
VNy = Vy - 0.2
if SecondStage == True:
NewCurrentX = New.xcor()
NewCurrentY = New.ycor()
d = math.sqrt(NewCurrentX ** 2 + NewCurrentY ** 2)
f = 17 / (d ** 2)
theta = math.atan2(NewCurrentY, NewCurrentX)
fx = math.cos(theta) * f
fy = math.sin(theta) * f
VNx += -fx
VNy += -fy
New.goto(New.xcor() + VNx, New.ycor() + VNy)
if d < 100:
New.color("white")
turtle.exitonclick()
|
AuthorI work as an actuary and underwriter at a global reinsurer in London. Categories
All
Archives
April 2024
|
 RSS Feed
RSS Feed