
In which we set up K-fold Cross Validation to assess model performance, spend quite a while tweaking our model, use hyper-parameter tuning, but then end up not actually improving our model. Source: https://somewan.design There are a few things I'd like to accomplish today, first I'd like to generate some sort of accuracy score just using the training data. So we're going to set up K-fold cross validation and explore how that works. Secondly there's some minor tweaks I'd like to make to the variables - encoding some of them differently, and adding a couple of new variables. Finally we're going to run hyper-parameter tuning to see if that increases our performance. Once we've got K-fold CV set up we'll be able to investigate this improvement in performance without uploading to Kaggle which will be interesting. Mobile users - once again, if the below is not rendering well, please try rotating to landscape view.
In [1]:
import os
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import RandomizedSearchCV
from sklearn.model_selection import cross_val_score
from sklearn.preprocessing import LabelEncoder
In [2]:
path = "C:\Work\Machine Learning experiments\Kaggle\House Price"
os.chdir(path)
In [3]:
train_data = pd.read_csv("train.csv")
test_data = pd.read_csv("test.csv")
In [4]:
features = ['Neighborhood','OverallQual','OverallCond','BldgType','HouseStyle']
Y = train_data['SalePrice']
X = pd.get_dummies(train_data[features])
X_test = pd.get_dummies(test_data[features])
columns = X.columns
ColList = columns.tolist()
missing_cols = set( X_test.columns ) - set( X.columns )
missing_cols2 = set( X.columns ) - set( X_test.columns )
# Add a missing column in test set with default value equal to 0
for c in missing_cols:
X[c] = 0
for c in missing_cols2:
X_test[c] = 0
# Ensure the order of column in the test set is in the same order than in train set
X = X[X_test.columns]
RFmodel = RandomForestRegressor(random_state=1)
RFmodel.fit(X,Y)
Out[4]:
RandomForestRegressor(random_state=1)
In [5]:
# Let's see how this model scores using cross validation
scores = cross_val_score(RFmodel, X, Y, cv=10)
scores
[scores.mean(), scores.std()]
Out[5]:
[0.7499322339157881, 0.029658128350339423]
In [6]:
# Okay we scored 75% according to the CV measure, let's run the same process on
# the other models we've set up so far, first the version where we drop all columns
# which have an Nan in them
TrainColumns = train_data.columns
frames = [train_data, test_data]
Total_data = pd.concat(frames)
features = []
featuresNotUsed = []
for i in TrainColumns:
if not(Total_data[i].isnull().values.any()):
if not(i == 'Id'):
if not(i == 'SalePrice'):
features.append(i)
else:
featuresNotUsed.append(i)
Y = train_data['SalePrice']
X = pd.get_dummies(train_data[features])
X_test = pd.get_dummies(test_data[features])
columns = X.columns
ColList = columns.tolist()
missing_cols = set( X_test.columns ) - set( X.columns )
missing_cols2 = set( X.columns ) - set( X_test.columns )
# Add a missing column in test set with default value equal to 0
for c in missing_cols:
X[c] = 0
for c in missing_cols2:
X_test[c] = 0
# Ensure the order of column in the test set is in the same order than in train set
X = X[X_test.columns]
RFmodel = RandomForestRegressor(random_state=1)
RFmodel.fit(X,Y)
predictions = RFmodel.predict(X_test)
In [7]:
scores = cross_val_score(RFmodel, X, Y, cv=10)
scores
[scores.mean(), scores.std()]
Out[7]:
[0.8408222755620794, 0.048773947402117185]
In [8]:
# Okay our score has improved, we're now at around 85%, let's try the version
# where we fill in all the Nan with 0s
features= TrainColumns[1:79]
for i in features:
train_data[i] = train_data[i].fillna(0)
test_data[i] = test_data[i].fillna(0)
Y = train_data['SalePrice']
X = pd.get_dummies(train_data[features])
X_test = pd.get_dummies(test_data[features])
columns = X.columns
ColList = columns.tolist()
missing_cols = set( X_test.columns ) - set( X.columns )
missing_cols2 = set( X.columns ) - set( X_test.columns )
# Add a missing column in test set with default value equal to 0
for c in missing_cols:
X[c] = 0
for c in missing_cols2:
X_test[c] = 0
# Ensure the order of column in the test set is in the same order than in train set
X = X[X_test.columns]
RFmodel = RandomForestRegressor(random_state=1)
RFmodel.fit(X,Y)
Out[8]:
RandomForestRegressor(random_state=1)
In [9]:
scores = cross_val_score(RFmodel, X, Y, cv=10)
scores
[scores.mean(), scores.std()]
Out[9]:
[0.858899065803126, 0.05176910554982082]
In [10]:
# Okay, we've used CV and tested our three models 'internally' rather
# than against the test set, and we've got broadly similar answers.
# Our first model scored about 75%, our second 85%, and our third 86%.
# Interestingly, our Std Dev went up at each step, which matches what
# we would expect, our model has become more accurate but at the cost of
# becoming more complex, and moving towards over-fitting
# Let's run some hyper-parameter tuning on our most successful model
#%%Set up space of possible hyper-params
# Number of trees in random forest
n_estimators = [int(x) for x in np.linspace(start = 200, stop = 2000, num = 10)]
# Number of features to consider at every split
max_features = ['auto', 'sqrt']
# Maximum number of levels in tree
max_depth = [int(x) for x in np.linspace(10, 110, num = 11)]
max_depth.append(None)
# Minimum number of samples required to split a node
min_samples_split = [2, 5, 10]
# Minimum number of samples required at each leaf node
min_samples_leaf = [1, 2, 4]
# Method of selecting samples for training each tree
bootstrap = [True, False]
# Create the random grid
random_grid = {'n_estimators': n_estimators,
'max_features': max_features,
'max_depth': max_depth,
'min_samples_split': min_samples_split,
'min_samples_leaf': min_samples_leaf,
'bootstrap': bootstrap}
print(random_grid)
{'n_estimators': [200, 400, 600, 800, 1000, 1200, 1400, 1600, 1800, 2000], 'max_features': ['auto', 'sqrt'], 'max_depth': [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, None], 'min_samples_split': [2, 5, 10], 'min_samples_leaf': [1, 2, 4], 'bootstrap': [True, False]}
In [11]:
RFmodel = RandomForestRegressor(random_state=1)
# Random search of parameters, using 3 fold cross validation,
# search across 100 different combinations, and use all available cores
RFmodel_random = RandomizedSearchCV(estimator = RFmodel, param_distributions = random_grid, n_iter = 10, cv = 3, verbose=2, random_state=1, n_jobs = -1)
# Fit the random search model
RFmodel_random.fit(X, Y)
Fitting 3 folds for each of 10 candidates, totalling 30 fits [Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 30 out of 30 | elapsed: 2.4min finished
Out[11]:
RandomizedSearchCV(cv=3, estimator=RandomForestRegressor(random_state=1),
n_jobs=-1,
param_distributions={'bootstrap': [True, False],
'max_depth': [10, 20, 30, 40, 50, 60,
70, 80, 90, 100, 110,
None],
'max_features': ['auto', 'sqrt'],
'min_samples_leaf': [1, 2, 4],
'min_samples_split': [2, 5, 10],
'n_estimators': [200, 400, 600, 800,
1000, 1200, 1400, 1600,
1800, 2000]},
random_state=1, verbose=2)
In [13]:
RFmodel_random.best_params_
Out[13]:
{'n_estimators': 1600,
'min_samples_split': 2,
'min_samples_leaf': 1,
'max_features': 'sqrt',
'max_depth': 40,
'bootstrap': False}
In [14]:
scores = cross_val_score(RFmodel_random, X, Y, cv=10)
scores
[scores.mean(), scores.std()]
Fitting 3 folds for each of 10 candidates, totalling 30 fits [Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 30 out of 30 | elapsed: 1.9min finished Fitting 3 folds for each of 10 candidates, totalling 30 fits [Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 30 out of 30 | elapsed: 1.9min finished Fitting 3 folds for each of 10 candidates, totalling 30 fits [Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 30 out of 30 | elapsed: 1.9min finished Fitting 3 folds for each of 10 candidates, totalling 30 fits [Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 30 out of 30 | elapsed: 1.9min finished Fitting 3 folds for each of 10 candidates, totalling 30 fits [Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 30 out of 30 | elapsed: 2.1min finished Fitting 3 folds for each of 10 candidates, totalling 30 fits [Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 30 out of 30 | elapsed: 1.9min finished Fitting 3 folds for each of 10 candidates, totalling 30 fits [Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 30 out of 30 | elapsed: 2.0min finished Fitting 3 folds for each of 10 candidates, totalling 30 fits [Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 30 out of 30 | elapsed: 2.0min finished Fitting 3 folds for each of 10 candidates, totalling 30 fits [Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 30 out of 30 | elapsed: 1.9min finished Fitting 3 folds for each of 10 candidates, totalling 30 fits [Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 30 out of 30 | elapsed: 1.9min finished
Out[14]:
[0.8686354196314181, 0.039199207651046085]
In [15]:
# While setting up the previous version I realised that we'd missed out
# one variable - Sale Condition had not been included, let's quickly
# re-run the model, but including this.
train_data = pd.read_csv("train.csv")
test_data = pd.read_csv("test.csv")
features= TrainColumns[1:80]
for i in features:
train_data[i] = train_data[i].fillna(0)
test_data[i] = test_data[i].fillna(0)
Y = train_data['SalePrice']
X = pd.get_dummies(train_data[features])
X_test = pd.get_dummies(test_data[features])
columns = X.columns
ColList = columns.tolist()
missing_cols = set( X_test.columns ) - set( X.columns )
missing_cols2 = set( X.columns ) - set( X_test.columns )
# Add a missing column in test set with default value equal to 0
for c in missing_cols:
X[c] = 0
for c in missing_cols2:
X_test[c] = 0
# Ensure the order of column in the test set is in the same order than in train set
X = X[X_test.columns]
RFmodel = RandomForestRegressor(random_state=1)
RFmodel.fit(X,Y)
Out[15]:
RandomForestRegressor(random_state=1)
In [16]:
scores = cross_val_score(RFmodel, X, Y, cv=10)
scores
[scores.mean(), scores.std()]
Out[16]:
[0.859128262549325, 0.0536366209565343]
In [17]:
# Let's add try a few tweaks and see how our score changes
# I've been reading a few online tutorials, and there are a
# few things people have done which seem to like good ideas
# First - some of the categorical variables have an ordering
# whereas we've encoded them just using onehotencoding
# e.g. Exterior Quality comes in the form 'good/average/excellent'
# Whereas we've ignored this ordering
# Taken from the following:
# https://www.kaggle.com/serigne/stacked-regressions-top-4-on-leaderboard
train_data = pd.read_csv("train.csv")
test_data = pd.read_csv("test.csv")
frames = [train_data, test_data]
total_data = pd.concat(frames)
cols = ('FireplaceQu', 'BsmtQual', 'BsmtCond', 'GarageQual', 'GarageCond',
'ExterQual', 'ExterCond','HeatingQC', 'PoolQC', 'KitchenQual', 'BsmtFinType1',
'BsmtFinType2', 'Functional', 'Fence', 'BsmtExposure', 'GarageFinish', 'LandSlope',
'LotShape', 'PavedDrive', 'Street', 'Alley', 'CentralAir', 'MSSubClass', 'OverallCond',
'YrSold', 'MoSold')
# process columns, apply LabelEncoder to categorical features
for c in cols:
lbl = LabelEncoder()
lbl.fit(list(total_data[c].values))
total_data[c] = lbl.transform(list(total_data[c].values))
train_data = total_data[0:1460]
test_data = total_data[1460:2919]
features = total_data.columns
features = features.drop('Id')
features = features.drop('SalePrice')
features
Out[17]:
Index(['MSSubClass', 'MSZoning', 'LotFrontage', 'LotArea', 'Street', 'Alley',
'LotShape', 'LandContour', 'Utilities', 'LotConfig', 'LandSlope',
'Neighborhood', 'Condition1', 'Condition2', 'BldgType', 'HouseStyle',
'OverallQual', 'OverallCond', 'YearBuilt', 'YearRemodAdd', 'RoofStyle',
'RoofMatl', 'Exterior1st', 'Exterior2nd', 'MasVnrType', 'MasVnrArea',
'ExterQual', 'ExterCond', 'Foundation', 'BsmtQual', 'BsmtCond',
'BsmtExposure', 'BsmtFinType1', 'BsmtFinSF1', 'BsmtFinType2',
'BsmtFinSF2', 'BsmtUnfSF', 'TotalBsmtSF', 'Heating', 'HeatingQC',
'CentralAir', 'Electrical', '1stFlrSF', '2ndFlrSF', 'LowQualFinSF',
'GrLivArea', 'BsmtFullBath', 'BsmtHalfBath', 'FullBath', 'HalfBath',
'BedroomAbvGr', 'KitchenAbvGr', 'KitchenQual', 'TotRmsAbvGrd',
'Functional', 'Fireplaces', 'FireplaceQu', 'GarageType', 'GarageYrBlt',
'GarageFinish', 'GarageCars', 'GarageArea', 'GarageQual', 'GarageCond',
'PavedDrive', 'WoodDeckSF', 'OpenPorchSF', 'EnclosedPorch', '3SsnPorch',
'ScreenPorch', 'PoolArea', 'PoolQC', 'Fence', 'MiscFeature', 'MiscVal',
'MoSold', 'YrSold', 'SaleType', 'SaleCondition'],
dtype='object')
In [18]:
pd.options.mode.chained_assignment = None # default='warn'
In [19]:
for i in features:
train_data[i] = train_data[i].fillna(0)
test_data[i] = test_data[i].fillna(0)
Y = train_data['SalePrice']
X = pd.get_dummies(train_data[features])
X_test = pd.get_dummies(test_data[features])
columns = X.columns
ColList = columns.tolist()
missing_cols = set( X_test.columns ) - set( X.columns )
missing_cols2 = set( X.columns ) - set( X_test.columns )
# Add a missing column in test set with default value equal to 0
for c in missing_cols:
X[c] = 0
for c in missing_cols2:
X_test[c] = 0
# Ensure the order of column in the test set is in the same order than in train set
X = X[X_test.columns]
RFmodel = RandomForestRegressor(random_state=1)
RFmodel.fit(X,Y)
Out[19]:
RandomForestRegressor(random_state=1)
In [20]:
scores = cross_val_score(RFmodel, X, Y, cv=10)
scores
[scores.mean(), scores.std()]
Out[20]:
[0.8602885832464457, 0.05312459024978507]
In [21]:
# Okay, so that change seems to have done very little to improve the model
# we've decreased our score by less than 1%
In [22]:
# Let's try one more thing - let's add another variable corresponding
# to total sqr footage, note this is also taken from :
# https://www.kaggle.com/serigne/stacked-regressions-top-4-on-leaderboard
train_data = pd.read_csv("train.csv")
test_data = pd.read_csv("test.csv")
In [23]:
features= TrainColumns[1:80]
for i in features:
train_data[i] = train_data[i].fillna(0)
test_data[i] = test_data[i].fillna(0)
frames = [train_data, test_data]
total_data = pd.concat(frames)
total_data['TotalSF'] = total_data['TotalBsmtSF'] + total_data['1stFlrSF'] + total_data['2ndFlrSF']
In [24]:
features = total_data.columns
features = features.drop('Id')
features = features.drop('SalePrice')
features
Out[24]:
Index(['MSSubClass', 'MSZoning', 'LotFrontage', 'LotArea', 'Street', 'Alley',
'LotShape', 'LandContour', 'Utilities', 'LotConfig', 'LandSlope',
'Neighborhood', 'Condition1', 'Condition2', 'BldgType', 'HouseStyle',
'OverallQual', 'OverallCond', 'YearBuilt', 'YearRemodAdd', 'RoofStyle',
'RoofMatl', 'Exterior1st', 'Exterior2nd', 'MasVnrType', 'MasVnrArea',
'ExterQual', 'ExterCond', 'Foundation', 'BsmtQual', 'BsmtCond',
'BsmtExposure', 'BsmtFinType1', 'BsmtFinSF1', 'BsmtFinType2',
'BsmtFinSF2', 'BsmtUnfSF', 'TotalBsmtSF', 'Heating', 'HeatingQC',
'CentralAir', 'Electrical', '1stFlrSF', '2ndFlrSF', 'LowQualFinSF',
'GrLivArea', 'BsmtFullBath', 'BsmtHalfBath', 'FullBath', 'HalfBath',
'BedroomAbvGr', 'KitchenAbvGr', 'KitchenQual', 'TotRmsAbvGrd',
'Functional', 'Fireplaces', 'FireplaceQu', 'GarageType', 'GarageYrBlt',
'GarageFinish', 'GarageCars', 'GarageArea', 'GarageQual', 'GarageCond',
'PavedDrive', 'WoodDeckSF', 'OpenPorchSF', 'EnclosedPorch', '3SsnPorch',
'ScreenPorch', 'PoolArea', 'PoolQC', 'Fence', 'MiscFeature', 'MiscVal',
'MoSold', 'YrSold', 'SaleType', 'SaleCondition', 'TotalSF'],
dtype='object')
In [25]:
cols = ('FireplaceQu', 'BsmtQual', 'BsmtCond', 'GarageQual', 'GarageCond',
'ExterQual', 'ExterCond','HeatingQC', 'PoolQC', 'KitchenQual', 'BsmtFinType1',
'BsmtFinType2', 'Functional', 'Fence', 'BsmtExposure', 'GarageFinish', 'LandSlope',
'LotShape', 'PavedDrive', 'Street', 'Alley', 'CentralAir', 'MSSubClass', 'OverallCond',
'YrSold', 'MoSold')
# process columns, apply LabelEncoder to categorical features
for c in cols:
lbl = LabelEncoder()
lbl.fit(list(total_data[c].values))
total_data[c] = lbl.transform(list(total_data[c].values))
train_data = total_data[0:1460]
test_data = total_data[1460:2919]
Y = train_data['SalePrice']
X = pd.get_dummies(train_data[features])
X_test = pd.get_dummies(test_data[features])
columns = X.columns
ColList = columns.tolist()
missing_cols = set( X_test.columns ) - set( X.columns )
missing_cols2 = set( X.columns ) - set( X_test.columns )
# Add a missing column in test set with default value equal to 0
for c in missing_cols:
X[c] = 0
for c in missing_cols2:
X_test[c] = 0
# Ensure the order of column in the test set is in the same order than in train set
X = X[X_test.columns]
RFmodel = RandomForestRegressor(random_state=1)
RFmodel.fit(X,Y)
Out[25]:
RandomForestRegressor(random_state=1)
In [26]:
scores = cross_val_score(RFmodel, X, Y, cv=10)
scores
[scores.mean(), scores.std()]
Out[26]:
[0.8667013439741871, 0.04532036910923081]
In [ ]:
# This actually appears to improve our model!
# Let's quickly run hyper-parameter tuning on this version
# which will combine the best of all we have done above
In [27]:
#%%Set up space of possible hyper-params
# Number of trees in random forest
n_estimators = [int(x) for x in np.linspace(start = 200, stop = 2000, num = 10)]
# Number of features to consider at every split
max_features = ['auto', 'sqrt']
# Maximum number of levels in tree
max_depth = [int(x) for x in np.linspace(10, 110, num = 11)]
max_depth.append(None)
# Minimum number of samples required to split a node
min_samples_split = [2, 5, 10]
# Minimum number of samples required at each leaf node
min_samples_leaf = [1, 2, 4]
# Method of selecting samples for training each tree
bootstrap = [True, False]
# Create the random grid
random_grid = {'n_estimators': n_estimators,
'max_features': max_features,
'max_depth': max_depth,
'min_samples_split': min_samples_split,
'min_samples_leaf': min_samples_leaf,
'bootstrap': bootstrap}
In [28]:
RFmodel = RandomForestRegressor(random_state=1)
# Random search of parameters, using 3 fold cross validation,
# search across 100 different combinations, and use all available cores
RFmodel_random = RandomizedSearchCV(estimator = RFmodel, param_distributions = random_grid, n_iter = 30, cv = 3, verbose=2, random_state=1, n_jobs = -1)
# Fit the random search model
RFmodel_random.fit(X, Y)
predictions = RFmodel_random.predict(X_test)
Fitting 3 folds for each of 30 candidates, totalling 90 fits [Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 25 tasks | elapsed: 1.6min [Parallel(n_jobs=-1)]: Done 90 out of 90 | elapsed: 4.6min finished
In [29]:
RFmodel_random.best_params_
Out[29]:
{'n_estimators': 1600,
'min_samples_split': 2,
'min_samples_leaf': 1,
'max_features': 'sqrt',
'max_depth': 40,
'bootstrap': False}
In [30]:
RFmodel = RandomForestRegressor(n_estimators = 1600,
min_samples_split = 2,
min_samples_leaf = 1,
max_features = 'sqrt',
max_depth= 40,
bootstrap= False,
random_state=1)
In [31]:
scores = cross_val_score(RFmodel, X, Y, cv=10)
scores
[scores.mean(), scores.std()]
Out[31]:
[0.877473773223001, 0.03875787125404092]
In [65]:
scores = cross_val_score(RFmodel_random, X, Y, cv=5)
scores
[scores.mean(), scores.std()]
Fitting 3 folds for each of 30 candidates, totalling 90 fits [Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 25 tasks | elapsed: 1.1min [Parallel(n_jobs=-1)]: Done 90 out of 90 | elapsed: 3.5min finished Fitting 3 folds for each of 30 candidates, totalling 90 fits [Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 25 tasks | elapsed: 1.2min [Parallel(n_jobs=-1)]: Done 90 out of 90 | elapsed: 3.3min finished Fitting 3 folds for each of 30 candidates, totalling 90 fits [Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 25 tasks | elapsed: 1.1min [Parallel(n_jobs=-1)]: Done 90 out of 90 | elapsed: 3.2min finished Fitting 3 folds for each of 30 candidates, totalling 90 fits [Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 25 tasks | elapsed: 1.1min [Parallel(n_jobs=-1)]: Done 90 out of 90 | elapsed: 3.1min finished Fitting 3 folds for each of 30 candidates, totalling 90 fits [Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers. [Parallel(n_jobs=-1)]: Done 25 tasks | elapsed: 1.1min [Parallel(n_jobs=-1)]: Done 90 out of 90 | elapsed: 3.1min finished
Out[65]:
[0.8769289170485848, 0.02251117120317736]
In [66]:
output = pd.DataFrame({'ID': test_data.Id, 'SalePrice': predictions})
output.to_csv('my_submission - V4 - RF.csv',index=False)
And all that remains is to upload our latest submission as see how it performs. Fingers crossed. 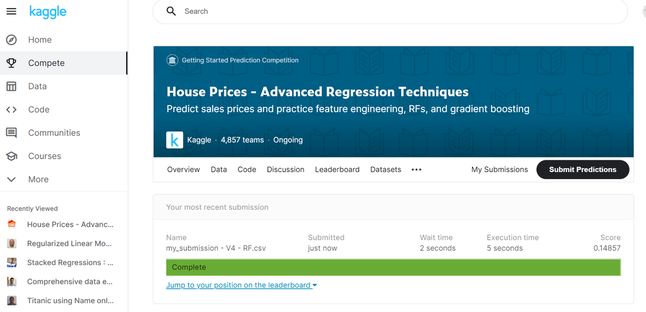
And our score has not actually improved! hmmmm.. I'm slightly stumped here as I really thought it would improve given we've tided up our variables, and we've added hyper-parameter tuning. There's a few possibilities:
So that's all for today. Slightly disappointing that we didn't improve out score, but we did learn a few new tricks which will hopefully come in useful later on. Tune in next time when we have our final attempt at the House Price Kaggle competition. |
AuthorI work as an actuary and underwriter at a global reinsurer in London. Categories
All
Archives
April 2024
|
 RSS Feed
RSS Feed
Leave a Reply.