An Actuary learns Machine Learning - Part 8 - Data Cleaning / more Null Values / more Random Forests6/2/2021 
In which we deal with those pesky null values, add additional variables to our Random Forest model, but only actually improve our score by a marginal amount. Source: https://somewan.design The task today is fairly simple, last time we excluded a number of variables from our model due to the fact that some entries had null values, and the Random Forest Algorithm could not handle any columns containing null values. This time, we're going to replace the null values in a vaguely sensible way, so as to be able to bring in these additional variables, and hopefully improve our model in the process. So without further ado, here is the Notebook for today (Mobile users are recommended to go into landscape mode)
In [26]:
import os
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
In [6]:
path = "C:\Work\Machine Learning experiments\Kaggle\House Price"
os.chdir(path)
In [27]:
train_data = pd.read_csv("train.csv")
test_data = pd.read_csv("test.csv")
In [28]:
train_data.iloc[1:,1:7]
Out[28]:
1459 rows × 6 columns
In [29]:
# We see above that the 'Alley' column has a large number of 'NaN' which the
# Random Forests algorithm fell down on when we tried to use last time
# We need to replace these.
TrainColumns = train_data.columns
train_data.columns
Out[29]:
Index(['Id', 'MSSubClass', 'MSZoning', 'LotFrontage', 'LotArea', 'Street',
'Alley', 'LotShape', 'LandContour', 'Utilities', 'LotConfig',
'LandSlope', 'Neighborhood', 'Condition1', 'Condition2', 'BldgType',
'HouseStyle', 'OverallQual', 'OverallCond', 'YearBuilt', 'YearRemodAdd',
'RoofStyle', 'RoofMatl', 'Exterior1st', 'Exterior2nd', 'MasVnrType',
'MasVnrArea', 'ExterQual', 'ExterCond', 'Foundation', 'BsmtQual',
'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinSF1',
'BsmtFinType2', 'BsmtFinSF2', 'BsmtUnfSF', 'TotalBsmtSF', 'Heating',
'HeatingQC', 'CentralAir', 'Electrical', '1stFlrSF', '2ndFlrSF',
'LowQualFinSF', 'GrLivArea', 'BsmtFullBath', 'BsmtHalfBath', 'FullBath',
'HalfBath', 'BedroomAbvGr', 'KitchenAbvGr', 'KitchenQual',
'TotRmsAbvGrd', 'Functional', 'Fireplaces', 'FireplaceQu', 'GarageType',
'GarageYrBlt', 'GarageFinish', 'GarageCars', 'GarageArea', 'GarageQual',
'GarageCond', 'PavedDrive', 'WoodDeckSF', 'OpenPorchSF',
'EnclosedPorch', '3SsnPorch', 'ScreenPorch', 'PoolArea', 'PoolQC',
'Fence', 'MiscFeature', 'MiscVal', 'MoSold', 'YrSold', 'SaleType',
'SaleCondition', 'SalePrice'],
dtype='object')
In [31]:
# The issue we had last time with using all the variables is that the Random Forests
# did not like the null values in some of the columns, which led us to drop those columns.
# To bring them back in, we are going to have to replace the null values in the training
# and test set.
# I quickly looked through where the null values were, and generally they could just be
# replaced with a 0. For values such as LotArea which were null when the house did not
# have a Lot, it makes sense to use 0. For columns that used null when a values was unknown,
# I think it's still okay to use 0 - we are going to encode all our numerical variables
# anyway, so as long as we treat everything consistently, 0 will just replace 'unknown'.
# In the next part, I split out the columns with null values, and those without. This step
# was not strictly neccessary, but I think it's useful as a sense check of what we are doing.
features= TrainColumns[1:79]
for i in features:
train_data[i] = train_data[i].fillna(0)
test_data[i] = test_data[i].fillna(0)
In [33]:
train_data.iloc[1:,1:7]
Out[33]:
1459 rows × 6 columns
In [32]:
# We can see that the Alley column has now got 0s in place of Nan
# Which means we can now use this column in our Random Forest
Y = train_data['SalePrice']
In [18]:
X = pd.get_dummies(train_data[features])
X_test = pd.get_dummies(test_data[features])
In [19]:
columns = X.columns
ColList = columns.tolist()
missing_cols = set( X_test.columns ) - set( X.columns )
missing_cols2 = set( X.columns ) - set( X_test.columns )
# Add a missing column in test set with default value equal to 0
for c in missing_cols:
X[c] = 0
for c in missing_cols2:
X_test[c] = 0
# Ensure the order of column in the test set is in the same order than in train set
X = X[X_test.columns]
In [20]:
X.iloc[1:10,1:5]
Out[20]:
In [22]:
X_test.iloc[1:10,1:5]
Out[22]:
In [23]:
RFmodel = RandomForestRegressor(random_state=1)
RFmodel.fit(X,Y)
predictions = RFmodel.predict(X_test)
In [40]:
output = pd.DataFrame({'ID': test_data.Id, 'SalePrice': predictions})
output.to_csv('my_submission - V3 - RF.csv',index=False)
And all that remains is to submit our predictions to Kaggle: 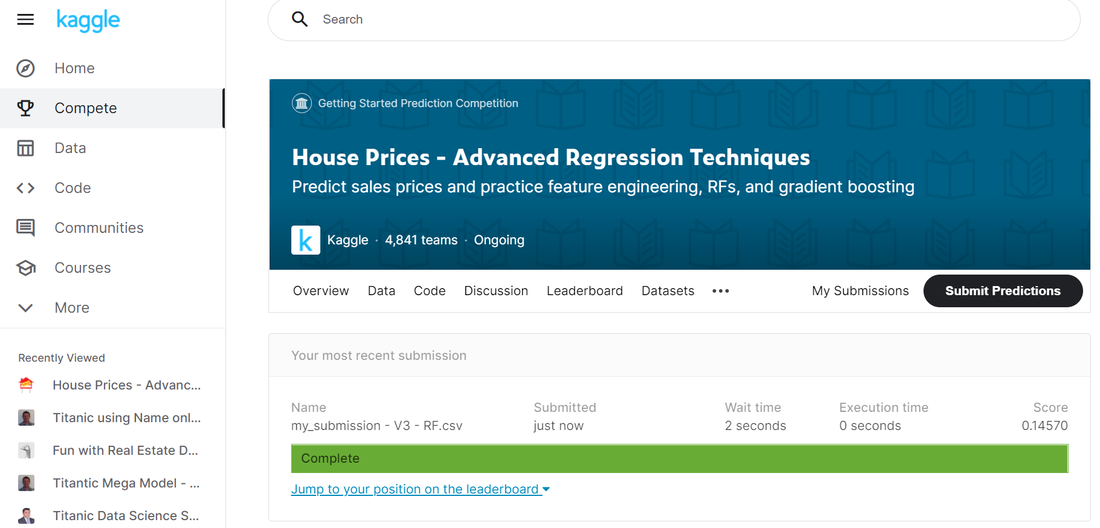
Okay, so we've improved our score - moving from 0.148 -> 0.146, which is good. We've also jumped up a few places on the leaderboard. That being said, the movement is actually pretty modest! We really didn't get much more out of our model by adding those extra variables, which is interesting. I would guess that either our Random Forests model is not fully exploiting the extra info, or more likely we've got tons of correlations and co-linearity in the variables. That's all for today, we made some progress but not much. Tune in next time when I'm planning on doing a couple of things - I want to get some sort of K-fold cross validation working, firstly to see how this approach compares to validating against the test set, and then secondly so that we can use this to start to play around with assessing whether we can get a better model by removing some of the correlations within the variables. |
AuthorI work as an actuary and underwriter at a global reinsurer in London. Categories
All
Archives
April 2024
|
 RSS Feed
RSS Feed
Leave a Reply.