
In which we start a new Kaggle challenge, try out a new Python IDE, build our first regression model, but most importantly - make these blog posts look much cleaner. Source: https://somewan.design
In this instalment we are moving on to a new Kaggle challenge – called “House Prices - Advanced Regression Techniques”. I’m going to go ahead and just paste in Kaggle’s description of the competition below rather than trying to rehash it:
Ask a home buyer to describe their dream house, and they probably won't begin with the height of the basement ceiling or the proximity to an east-west railroad. But this playground competition's dataset proves that much more influences price negotiations than the number of bedrooms or a white-picket fence. With 79 explanatory variables describing (almost) every aspect of residential homes in Ames, Iowa, this competition challenges you to predict the final price of each home. So the set-up is that we’ve got data on about 1500 houses sold in Iowa between 2007 and 2010, the dataset has info on all sorts of features of the properties – number of floors, size of lot, neighbourhood etc. Our job is to build a regression model which we will train on this dataset, and then use to predict the sale price of an additional 1500 houses. This challenge has some interesting differences and similarities compared to the previous Titanic challenge. Firstly, this is a regression challenge unlike Titanic which was a classification problem. In the Titanic challenge we were just making a single binary decision – did the person survive or die, here we are trying to pick an exact number as the sale price. Another difference which is clear right off the bat is the House Price dataset is much much richer – we’ve got 80 different variables for each sale. Just to give you a flavour, here are the first few: MSSubClass: The building class MSZoning: The general zoning classification LotFrontage: Linear feet of street connected to property LotArea: Lot size in square feet Street: Type of road access Alley: Type of alley access LotShape: General shape of property LandContour: Flatness of the property And each variable can take a number of different values, just looking at one variable at random – RoofStyle: RoofStyle: Type of roof Flat Flat Gable Gable Gambrel Gabrel (Barn) Hip Hip Mansard Mansard Shed Shed So I think part of the challenge here are going to be around not over-fitting, determining which are the important variables to focus our attentions on, dealing with correlations between variables and finding ways to visualise such a high-dimensional dataset. What about the similarities between this challenge and the titanic? Firstly it’s a supervised machine learning problem – we’ve got clear input and output variables to work from, we’re not just trying to spot abstract patterns in the data. Another similarity is that this problem is fairly static over time, we do have sales from a few different years, but it turns out this information is not actually too significant. Other machine learning problems such as the Kaggle competition ‘Predict Future prices’ are dependent on events happening over time and use time series methods, which adds an order of complexity to the analysis, not so here. Also, possibly worth mentioning before we get to the modelling - I’ve decided to drop Spyder and start using Jupyter notebook instead, and I already love it! For the type of analysis we’re doing, the notebook flows really nicely – I do miss having the variable explorer functionality. But more importantly from a ‘back-end’ perspective, I’ve realised I can just export the notebook as a html file, and then embed it directly into my website. Mobile users - the section below does not appear to be rendering particularly well for mobile users. If you rotate to landscape view it does get slightly better. As an alternative, I've also put the section below in a pdf on github: github.com/Lewis-Walsh/ActuaryLearnsMachineLearning-Part6/raw/main/ML6%20-%20main%20-%20Jupyter.pdf
In [4]:
import os
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
In [5]:
#First let’s add the Python code to change directories – I was doing this using the Spyder GUI before
#which is a bit lazy.
path = "C:\Work\Machine Learning experiments\Kaggle\House Price"
os.chdir(path)
In [7]:
train_data = pd.read_csv("train.csv")
test_data = pd.read_csv("test.csv")
In [8]:
#Let’s get our bearings by running some .head and .describe() commands on the training set and see
#that we spot:
train_data.head(n=20)
Out[8]:
20 rows × 81 columns
In [9]:
#We’ve certainly got lots of columns to work with – each row represents a sale, most of the
#columns describe the property itself, but over to the right we’ve also got some info on the
#sale (year sold, sale type, sale condition, etc.), and importantly – the variable we will be
#trying to predict – the sale price.
#Next let’s try the .describe command:
train_data.describe()
Out[9]:
8 rows × 38 columns
In [10]:
#Let’s pick out a few important features of the above – we’ve for 1460 rows, each row has a sale
# price – so far so good. The average sale price is $ 180,921. House prices in Iowa cira 2007
# are certainly a lot lower than London! We can read off the min and max house price – 35k, and
# 750k respectively. In order to start to build up some intuition around the dataset, let’s start
# to pick out some variables we think will be useful and graph them against house price:
#Let’s start with neighbourhood:
#First we need to pivot on Neighbourhood, sort by sales price, and then produce a bar chart:
NeighbourhoodPivot = train_data.groupby("Neighborhood")['SalePrice'].mean()
NeighbourhoodPivot = NeighbourhoodPivot.sort_values()
NeighbourhoodPivot.plot.bar()
Out[10]:
<AxesSubplot:xlabel='Neighborhood'> 
In [11]:
#The built-in .plot functionality is definitely not the prettiest, but at least it seems to work
# well straight out of the box. I’ve used Seaborn in the past, but since this is just a rough first
# cut, let’s not go to the effort right now just for the sake of appearance.
#So what can we deduce from the chart? We see that Neighbourhood is clearly going to be useful –
# NoRidge has an average sale price almost double that of the average across our entire dataset,
# MedaowV has an average almost half of the whole population. We’ll definitely want to include
# this in our modelling.
#Let’s repeat the above with a few more variables, just eyeballing the list of variables, I like
# the look of OverallQuality, OverallCondition, BuildingType, Housestyle, and YearSold
#Overall Quality:
OverallQualPivot = train_data.groupby("OverallQual")['SalePrice'].mean().sort_values()
OverallQualPivot.plot.bar()
Out[11]:
<AxesSubplot:xlabel='OverallQual'> 
In [12]:
OverallCondPivot = train_data.groupby("OverallCond")['SalePrice'].mean().sort_values()
OverallCondPivot.plot.bar()
Out[12]:
<AxesSubplot:xlabel='OverallCond'> 
In [13]:
BldgTypePivot = train_data.groupby("BldgType")['SalePrice'].mean().sort_values()
BldgTypePivot.plot.bar()
Out[13]:
<AxesSubplot:xlabel='BldgType'> 
In [14]:
HouseStylePivot = train_data.groupby("HouseStyle")['SalePrice'].mean().sort_values()
HouseStylePivot.plot.bar()
Out[14]:
<AxesSubplot:xlabel='HouseStyle'> 
In [15]:
YrSoldPivot = train_data.groupby("YrSold")['SalePrice'].mean().sort_values()
YrSoldPivot.plot.bar()
Out[15]:
<AxesSubplot:xlabel='YrSold'> 
In [16]:
#Okay – we’ve done some data exploration, and there are clearly some useful variables in our dataset.
#Building a model:
#We want to build a supervised regression model – since we had so much success with Random Forests
# last time, I’m going to just use that this time – we’re going to only use the variables above that
# used useful and we’re not going to amend any data or tweak and hyperparameters – just to give
# ourselves a naïve benchmark so reference against. The following is just code which I’ve taken from
# the Titanic competition and amended to work here:
features = ['Neighborhood','OverallQual','OverallCond','BldgType','HouseStyle']
Y = train_data['SalePrice']
X = pd.get_dummies(train_data[features])
X_test = pd.get_dummies(test_data[features])
columns = X.columns
ColList = columns.tolist()
missing_cols = set( X_test.columns ) - set( X.columns )
missing_cols2 = set( X.columns ) - set( X_test.columns )
# Add a missing column in test set with default value equal to 0
for c in missing_cols:
X[c] = 0
for c in missing_cols2:
X_test[c] = 0
# Ensure the order of column in the test set is in the same order than in train set
X = X[X_test.columns]
In [17]:
RFmodel = RandomForestRegressor(random_state=1)
RFmodel.fit(X,Y)
predictions = RFmodel.predict(X_test)
In [ ]:
output = pd.DataFrame({'ID': test_data.Id, 'SalePrice': predictions})
output.to_csv('my_submission - V1 - RF.csv',index=False)
Submitting to Kaggle So we’ve got our csv of predictions, let’s upload and see how we’ve done: 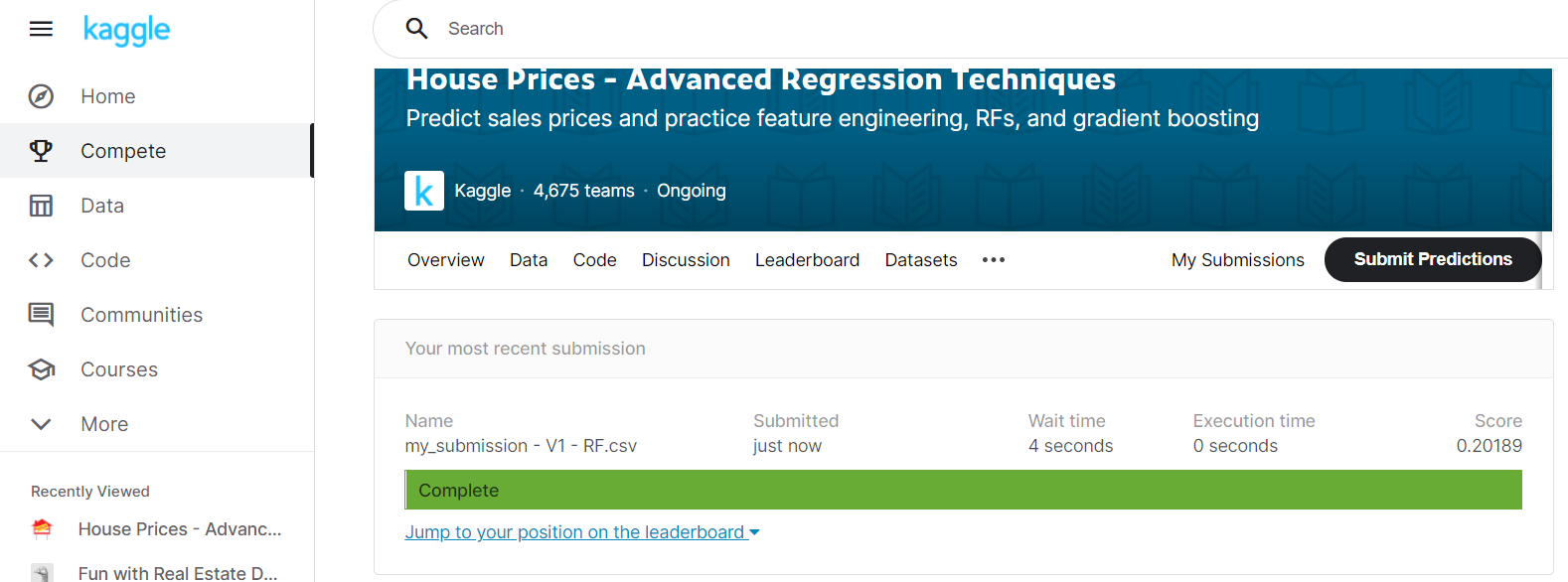
And we’ve achieved a score of 0.2018! Note in this context, a lower number is better – 0 denoting a perfect score where each SalePrice is predicted with 100% accuracy. This score places us in position 3760 of 4675. A lot of room for improvement, but let’s remember this is only a first cut of our model, there is a lot more to try – more data exploration, bring in additional variables, engineer our own features, try different ML models, tweak our hyper-parameters. Tune in next time when we investigate bringing more variables into play, draw an excessive number of graphs, and build a version 2 of our model |
AuthorI work as an actuary and underwriter at a global reinsurer in London. Categories
All
Archives
April 2024
|
 RSS Feed
RSS Feed
Leave a Reply.