An Actuary learns Machine Learning - Part 12 - Kaggle Tabular Playground Competition - June 2224/6/2022  In which we start a new Kaggle competition, submit a dummy attempt, and then build a very basic Excel model to establish a baseline for future progress. Source: https://somewan.design In the next few post I’ll be writing up my attempts at the June 22 Kaggle Tabular Playground competition. You can read about the competition here: https://www.kaggle.com/competitions/tabular-playground-series-jun-2022/overview Attempt 1 Let’s start by just submitting all 0s as our submission just to establish a baseline for our progression as we increase the sophistication of our model. This is the dummy submission file provided by Kaggle, so there is some logic to using 0 rather than another number. Doing so gives us the following score: 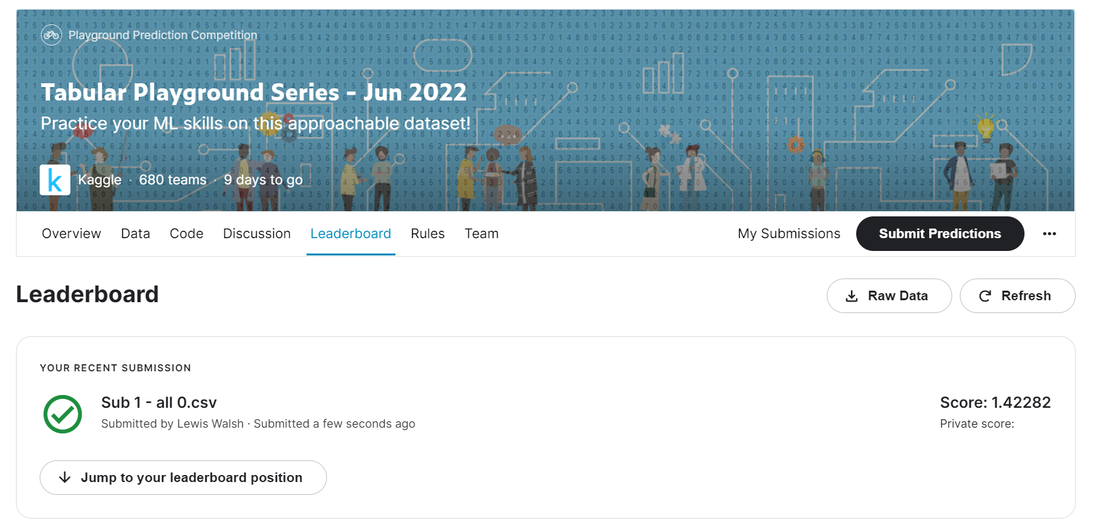 A public score of 1.42282, which places us in joint 646 out of 681 on the leaderboard. Interestingly, there’s a few people who have done substantially worse than this. The leaderboard tracks your best attempt, so some people have only submitted models which are worse than the dummy submission provided by Kaggle as part of the initial data download, yikes! Attempt 2 Now let’s build our first proper model. I’m still a fan of prototyping projects in Excel, which is possible a habit I should try to get out of, but it’s still where I’m most comfortable. For our first model, I’m going to use the median of a given column to impute the missing values. This is probably the most basic method we can use which is still based on some sort of statistical reasoning. Other options along the same lines would be to use the mean or mode of a given column, which we could try later, but for now I'm sticking with the median. Let’s open the data in Excel, and then add in the median for each column, and then for each missing value, lookup the relevant median: 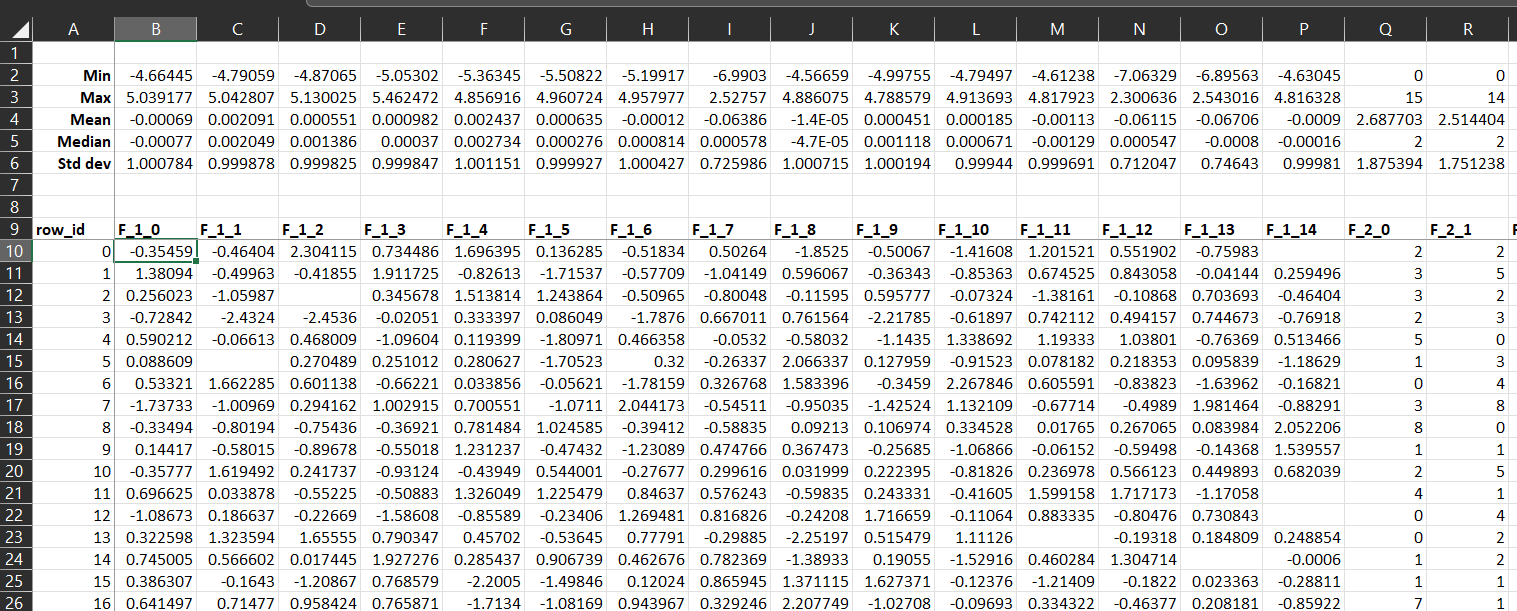 Pretty straight forward to set up. Now let’s submit this and see how much of an improvement it gives us: 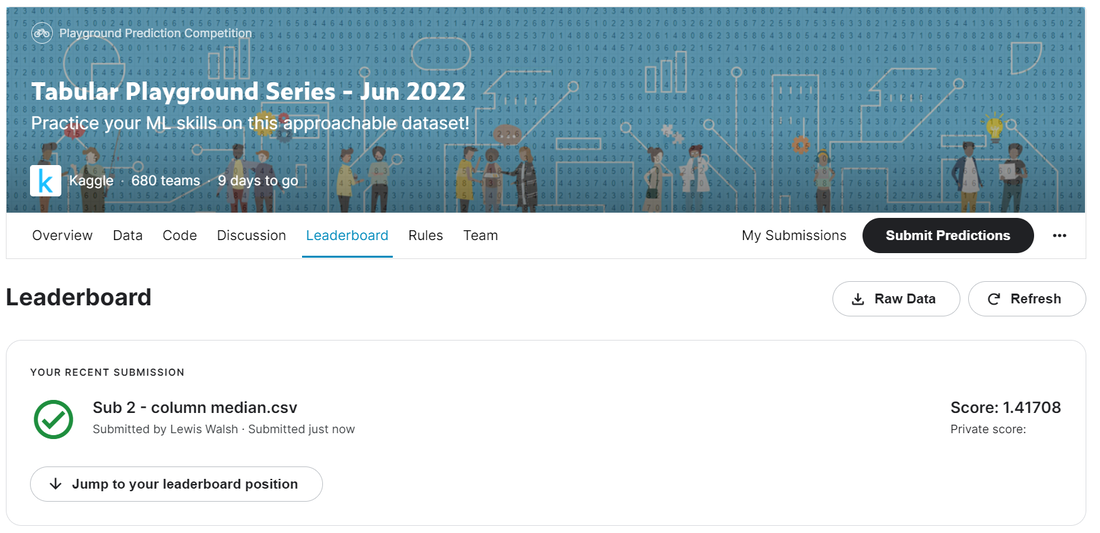 A very marginal improvement, 1.423 -> 1.417, but an improvement none the less. We are now up to 635 out of 681, so quite some way to go.
Conclusion That’s all for this time, there are a couple of clear next steps; we need to build up some intuition on the dataset to guide us towards selecting appropriate models and approaches. We haven't really done any EDA at all yet. Then we need to get the data into Python to speed up the workflow, so that we can try some more powerful models out. |
AuthorI work as an actuary and underwriter at a global reinsurer in London. Categories
All
Archives
April 2024
|
 RSS Feed
RSS Feed
Leave a Reply.