An Actuary learns Machine Learning - Part 11 - Titanic revisited & Gradient Boosting Classifiers8/10/2021 
In which we try out the best performing algorithm from our house price prediction problem - Gradient Boosted Regression - on the Titanic problem, but don't actually manage to improve on our old score... Source: https://somewan.design Why are we Gradient boosting the Titanic? To recap where we got to last time - in parts 1-5 of this series we worked on the Kaggle Titanic competition. The idea of the competition is that you are given information about whether a subset of passengers survived or died the sinking of the Titanic. The info included things like age, sex, class, etc,. The goal was to build a model which could then predict whether a different set of individuals survived or died during the sinking just based on their age, sec, etc.. We built a number of models and compared their performance - a simple pivot table model, Random Forests, KNN, SVM, etc., and we found that the best performing model was a Random Forest. In parts 6-10 we tackled a similar problem from the Kaggle website involving predicting house prices in San Francisco, for this problem we also built a number of models. and in this case, the best performing model was Gradient Boosting Regression. Since we didn't actually try the GBR on the Titanic dataset, I thought it would be interesting to quickly run this, since we've already got the data set up in the correct format, and see how it performs. Note we are technically going to use Gradient Boosting Classifier (not Regression). but the structure of the model is very similar. The code below is from the Jupyter notebook script :
In [1]:
#%% Do imports
import numpy as np
import pandas as pd
from sklearn.ensemble import GradientBoostingClassifier
In [2]:
#%% Load test and train data
train_data = pd.read_csv("C:\\Kaggle\\Titanic\\train4.csv")
test_data = pd.read_csv("C:\\Kaggle\\Titanic\\test4.csv")
In [3]:
#%% Set-up model
Y = train_data["Survived"]
features = ["Pclass","Sex","SibSp","Parch","Embarked","AgeBand","Title"]
X = pd.get_dummies(train_data[features])
X_test = pd.get_dummies(test_data[features])
columns = X.columns
ColList = columns.tolist()
missing_cols = set( X_test.columns ) - set( X.columns )
missing_cols2 = set( X.columns ) - set( X_test.columns )
# Add a missing column in test set with default value equal to 0
for c in missing_cols:
X[c] = 0
for c in missing_cols2:
X_test[c] = 0
# Ensure the order of column in the test set is in the same order than in train set
X = X[X_test.columns]
In [4]:
#%%
GBoost = GradientBoostingClassifier(n_estimators=32, learning_rate=0.1,
max_depth=4, max_features=6,
min_samples_leaf=15, min_samples_split=10, random_state =5)
GBoost.fit(X, Y)
predictions = GBoost.predict(X_test)
In [5]:
#%% Output
output = pd.DataFrame({'PassengerID': test_data.PassengerId, 'Survived': predictions})
output.to_csv('C:\\Kaggle\\Titanic\\submissions\\my_submission v4 - GBC.csv',index=False)
Results All we really had to do was add the fourth cell, and set up the Gradient boost model. The rest of the code is basically identical to that in part 5 of the series. Jumping straight to the final answer, here is a summary table of the performance of the various models: 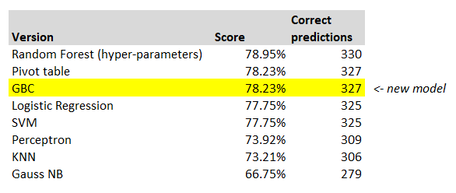
We see that Gradient Boosting Classifier placed in joint second place with the Pivot table model, but the Random Forest algorithm still holds the top spot. Note that the difference between the first and second placed models is actually pretty minimal - only 3 more correct predictions overall. Just to note, I did quickly run a version of the GBC with cross validated hyper-parameter tuning, to see whether this was the reason the Random Forest performed better, but it actually produced a worse result against the test data, so I did not include it in the above. So that's it for this experiment. I've kinda got used to these ML algorithms just constantly producing great results out of the box, so I was actually a bit surprised the GBC didn't just jump into first place. I think I've maybe adjusted my expectations too far the other way now. How would we go about improving our Titanic model if we wanted to? I've got a couple of ideas of areas to explore - I'd probably look at an Ensemble model of the best performing algorithms, and maybe try to bring in some extra features into the training set, such as family relations between passengers. But let's save both of those for another day. Next time I'm planning on tackling one of the following:
Tune in to find out which as I haven't decided yet! |
AuthorI work as an actuary and underwriter at a global reinsurer in London. Categories
All
Archives
April 2024
|
 RSS Feed
RSS Feed
Leave a Reply.